2.2 Random Variate Generation
This section will overview how to generate random variates using the KSL. A random variate is an observation of a random variable from some probability distribution. Appendix A describes four basic methods for generating random variates:
- inverse transform
- convolution
- acceptance/rejection
- mixture distributions
The KSL provides classes that facilitate these methods (and others).
2.2.1 Basic Random Variate Generation
In this section, we provide a couple of examples of generating random variates from “first principles”. The examples follow closely those presented in Appendix A.
Example 2.7 (Generating Exponential Random Variates) Consider a random variable, \(X\), that represents the time until failure for a machine tool. Suppose \(X\) is exponentially distributed with an expected value of \(1.\overline{33}\). Generate a random variate for the time until the first failure using a uniformly distributed value of \(u = 0.7\).
The function rExpo implements the inverse CDF function for the exponential distribution for any mean and any value of \(u\). By calling the function with the appropriate parameters, we can easily generate exponential random variates. Just as in Example A.2 of Appendix A the result is 1.6053. In this example, the value of \(u\) was given; however, it could have easily been generated using an instance of the RNStreamIfc interface and the randU01() function.
This next example illustrates how to generate negative binomial random variates via convolution.
Example 2.8 (Negative Binomial Variates Via Convolution) Use the following pseudo-random numbers \(u_{1} = 0.35\), \(u_{2} = 0.64\), \(u_{3} = 0.14\), generate a random variate from a shifted negative binomial distribution having parameters \(r=3\) and \(p= 0.3\).
Recall from Appendix A that we refer to the geometric distribution as the shifted geometric distribution, when \(X_{i}\sim Shifted\ Geometric(p)\) with range \(\{1, 2, 3, \dots\}\), and \(X_{i}\) can be generated via inverse transform with:
\[X_{i} = 1 + \left\lfloor \frac{ln(1 - U_{i})}{ln(1 - p)} \right\rfloor\] Note also that the shifted negative binomial distribution is just the sum of shifted geometric random variables. The code implements a function to generate a shifted geometric random variate. Because we need a shifted negative binomial with \(r=3\) and \(p=0.3\), the function is used three times to generate three shifted geometric random variates with \(p=0.3\). The observed values are summed to generate the shifted negative binomial. Just as in Example A.6 of Appendix A the result is 6.0.
As we will see in the next section, the concepts of Appendix A have been generalized and implemented within the ksl.utilities.random package for various common types of random variables.
2.2.2 Continuous and Discrete Random Variables
The KSL has the capability to generate random variates from both
discrete and continuous distributions. The ksl.utilities.random.rvariable package supports this functionality. The package has a set of interfaces
that define the behavior associated with random variables. Concrete
sub-classes of specific random variables are created by sub-classing
RVariable. As shown in Figure 2.3, every random variable has
access to an object that implements the RNStreamIfc interface. This
gives it the ability to generate pseudo-random numbers and to control
the streams. The GetValueIfc interface is the key interface because in
this context it returns a random value from the random variable. For
example, if d is a reference to an instance of a sub-class of type
RVariable, then d.value generates a random value.

Figure 2.3: Random Variable Interfaces
The names and parameters (based on common naming conventions) associated with the continuous random variables are as follows:
BetaRV(alpha1, alpha2)ChiSquaredRV(degreesOfFreedom)ExponentialRV(mean)GammaRV(shape, scale)GeneralizedBetaRV(alpha1, alpha2, min, max)JohnsonBRV(alpha1, alpha2, min, max)LaplaceRV(mean scale)LogLogisticRV(shape, scale)LognormalRV(mean, variance)NormalRV(mean, variance)PearsonType5RV(shape, scale)PearsonType6RV(alpha1, alpha2, beta)StudentTRV(degreesOfFreedom)TriangularRV(min, mode, max)UniformRV(min, max)WeibullRV(shape, scale)
NOTE! Be careful to note that the normal and lognormal random variables are specified with the mean and the variance (not the standard deviation). Because Kotlin has named parameters, a recommended good practice is to use the parameter names when creating the object instances. This reduces the chances that you have confused the parameters.
The names of the discrete random variables are as follows:
BernoulliRV(probOfSuccess)BinomialRV(pSucces, numTrials)ConstantRV(constVal)a degenerate probability mass on a single value that cannot be changedDEmpiricalRV(values, cdf)values is an array of numbers and cdf is an array representing the cumulative distribution function over the valuesDUniformRV(min, max)GeometricRV(probOfSucces)with range is 0 to infinityNegativeBinomialRV(probOfSuccess, numSuccess)with range is 0 to infinity. The number of failures before the \(r^{th}\) success.PoissonRV(mean)ShiftedGeometricRV(probOfSucces)range is 1 to infinityVConstantRV(constVal)a degenerate probability mass on a single value that can be changed
All classes that represent random variables also have optional parameters to specify the stream number and the random number stream provider. As noted for the NormalRV constructor, we see that the third
parameter, called streamNum, is used to specify the random number stream. The default stream provider is the provider associated with KSLRandom.
class NormalRV @JvmOverloads constructor(
val mean: Double = 0.0,
val variance: Double = 1.0,
streamNum: Int = 0,
streamProvider: RNStreamProviderIfc = KSLRandom.DefaultRNStreamProvider,
name: String? = null
) : ParameterizedRV(streamNum, streamProvider, name) If the stream number is not provided (i.e. the default of 0), then the next stream from the default provider is allocated to the new instance of the random variable. Thus, unless the programming specifically assigns streams, all random variables are automatically constructed such that they use different underlying streams.
As you can see, the name of the distribution followed by the letters RV designate the class names. Implementations of these classes extend the RVarable class, which implements the RVariableIfc interface. Users simply create an instance of the class and then use it to get a sequence of values that have the named probability distribution. In order to implement a new random variable (i.e. some random variable
that is not already implemented) you can extend the class
RVariable. This provides a basic template for what is expected
in the implementation. However, it implies that you need to implement
all of the required interfaces. The key method to implement is the
protected generate() method, which should return the generated random
value according to some algorithm.
In almost all cases, the KSL utilizes the inverse transform algorithm for generating random variates. Thus, there is a one to one mapping of the underlying pseudo-random number and the resulting random variate. Even in the case of distributions that do not have closed form inverse cumulative distribution functions, the KSL utilizes numerical methods to approximate the function whenever feasible. For example, the KSL uses a rational function approximation, see (Cody 1969), to implement the inverse cumulative distribution function for the standard normal distribution. The inversion for the gamma distribution is based on Algorithm AS 91 for inverting the chi-squared distribution and exploiting its relationship with the gamma distribution. The beta distribution also uses numerical methods to compute the cumulative distribution function as well as bi-section search to determine the inverse for the cumulative distribution function.
The KSL implements the BernoulliRV, DUniformRV, GeometricRV,
NegativeBinomialRV, and ShiftedGeometricRV classes using the methods
described in Chapter 2 of Rossetti (2015). While more efficient methods may be available, the
PoissonRV and BinomialRV distributions are implemented by searching the
probability mass functions. Both search methods use an approximation to
get close to the value of the inverse and then search up or down through
the cumulative distribution function. Because of this both distributions
use numerically stable methods to compute the cumulative distribution
function values. The DEmpiricalRV class also searches through the
cumulative distribution function.
The following sections will overview the generation algorithms and provide examples for using some of these distributions.
2.2.3 Creating and Using Random Variables
This section presents how to create and use random variables via KSL constructs. The basic approach is to create an instance of a specific type of random variable and use the instance to generate observations.
Example 2.9 (Generating Normal Random Variates) The following example code illustrates how to create a normal random variable and how to generate values using the value property. It is important to note that the value property will return a newly generated value each time that it is accessed.
fun main() {
// create a normal mean = 20.0, variance = 4.0 random variable,
// using stream number 1
val n = NormalRV(20.0, 4.0, streamNum = 1)
print(String.format("%3s %15s %n", "n", "Values"))
// generate some values
for (i in 1..5) {
// the value property returns a generated value
val x = n.value
print(String.format("%3d %15f %n", i, x))
}
}The resulting output is what you would expect.
n Values
1 17.718732
2 19.056360
3 19.003682
4 21.875759
5 18.466600 Alternatively, the user can use the sample() method to generate an array of values that can be later processed. The SampleIfc interface has the following useful functions:
sample()returns a new valuesample(sampleSize: Int)returns an array of valuessampleInto(values: DoubleArray)fills an array with valuessampleAsRows(sampleSize: Int, nRows: Int = 1)makes a 2-D array with samples in the rowssampleAsColumns(sampleSize: Int, nRows: Int = 1)makes a 2-D array with samples in the columnssampleInto(matrix: Array<DoubleArray>)fills a 2-D array with samples
NOTE!
Notice that the previous examples created the random variable outside of the loop that is used to generate values. This implements the best practice of creating an object once and using it many times. The NormalRV class was used outside of the loop to create the object and then used many times within the loop to get new random variates. It may not be an error to create random variables within loops, but it is generally bad practice and inefficient in terms of object creation. If you see yourself creating many instances of an object and then using it only one time before it is discarded, you should reconsider what you are doing.
The following code illustrates how to use the sample() function with a triangular distribution.
Example 2.10 (Using the sample() function) The following example code illustrates how to create a triangular random variable and how to generate values using the sample() function.
fun main() {
// create a triangular random variable with min = 2.0, mode = 5.0, max = 10.0
val t = TriangularRV(2.0, 5.0, 10.0, streamNum = 1)
// sample 5 values
val sample = t.sample(5)
print(String.format("%3s %15s %n", "n", "Values"))
for (i in sample.indices) {
print(String.format("%3d %15f %n", i + 1, sample[i]))
}
}Again, the output is what we would expect.
n Values
1 3.745929
2 4.764898
3 4.724053
4 7.360658
5 4.306321 NOTE!
The SampleIfc interface provides functionality to generate arrays of observations. The KSL provides extensive functionality for working with arrays within its utilities. This functionality is briefly discussed in Section D.7 of Appendix D.
It is important to note that the full range of functionality related to stream control is also available for random variables. That is, the underlying stream can be reset to its start, can be advanced to the next substream, can generate antithetic variates, etc. By default, if a random variable is created without specifying a stream number, the new instance of the random variable is supplied with its own unique stream. Since the underlying random number generator has an enormous number of streams, approximately \(1.8 \times 10^{19}\), it is very unlikely that the user will create so many streams as to start reusing them. However, the streams that are used by random variable instances can be supplied directly so that they may be shared by specifying a stream number.
Example 2.11 (Specifying a Stream) The following code example illustrates how to assign a specific stream by passing a specific stream number into the constructor of the random variable.
Within the underlying code, the previous example uses the default provider of the KSLRandom class to get stream 3 when constructing the instance of the normal random variable.
A discrete empirical random variable requires the specification of the values and their probabilities. This requires a little more setup. The user must supply the set of values that can be generated as well as an array holding the cumulative distribution probability across the values. The following code illustrates how to do this.
Example 2.12 (Using a DEmpirical Random Variable) The values are provided via an array and the probabilities must be specified in the form of the cumulative probabilities, such that the last element is 1.0.
fun main() {
// values is the set of possible values
val values = doubleArrayOf(1.0, 2.0, 3.0, 4.0)
// cdf is the cumulative distribution function over the values
val cdf = doubleArrayOf(1.0 / 6.0, 3.0 / 6.0, 5.0 / 6.0, 1.0)
//create a discrete empirical random variable
val n1 = DEmpiricalRV(values, cdf, streamNum = 1)
println(n1)
print(String.format("%3s %15s %n", "n", "Values"))
for (i in 1..5) {
print(String.format("%3d %15f %n", i, n1.value))
}
println()
println(n1.probabilityPoints)
}The results are as follows:
DEmpiricalRV(values=[1.0, 2.0, 3.0, 4.0], cdf=[0.16666666666666666, 0.5, 0.8333333333333334, 1.0])
n Values
1 1.000000
2 2.000000
3 2.000000
4 3.000000
5 2.000000 Section A.2.4 of Appendix A defines mixture and truncated distributions. The following provides examples of how to create and use random variables from these distributions. The examples follow those presented in Section A.2.4.
Example 2.13 (Mixture Distribution) Suppose the time that it takes to pay with a credit card, \(X_{1}\), is exponentially distributed with a mean of \(1.5\) minutes and the time that it takes to pay with cash, \(X_{2}\), is exponentially distributed with a mean of \(1.1\) minutes. In addition, suppose that the chance that a person pays with credit is 70%. Then, the overall distribution representing the payment service time, \(X\), has an hyper-exponential distribution with parameters \(\omega_{1} = 0.7\), \(\omega_{2} = 0.3\), \(\lambda_{1} = 1/1.5\), and \(\lambda_{2} = 1/1.1\). Generate 5 random variates from this distribution.
fun main() {
// rvs is the list of random variables for the mixture
val rvs = listOf(ExponentialRV(1.5), ExponentialRV(1.1))
// cdf is the cumulative distribution function over the random variables
val cdf = doubleArrayOf(0.7, 1.0)
//create a mixture random variable
val he = MixtureRV(rvs, cdf, streamNum = 1)
print(String.format("%3s %15s %n", "n", "Values"))
for (i in 1..5) {
print(String.format("%3d %15f %n", i, he.value))
}
} n Values
1 0.575249
2 2.621730
3 1.143410
4 0.659060
5 2.114972 The MixtureRV class requires a list of random variables and a specification of the probability associated with each random variable in the form of a cumulative distribution function. In the provided code sample, a list is created holding the two exponential random variables. Since the distribution associated with the credit card payment is first in the list, the probability of 0.7 is specified first in the cdf array.
The next example illustrates how to generate from a truncated distribution. A truncated distribution is a distribution derived from another distribution for which the range of the random variable is restricted. Suppose we have a random variable, \(X\) with PDF, \(f(x)\) and CDF \(F(x)\). Suppose that we want to constrain \(f(x)\) over interval \([a, b]\), where \(a<b\) and the interval \([a, b]\) is a subset of the original support of \(f(x)\). Note that it is possible that \(a = -\infty\) or \(b = +\infty\). This leads to a random variable from a truncated distribution \(F^{*}(x)\) having CDF:
\[ F^{*}(x) = \begin{cases} 0 & \text{if} \; x < a \\ \frac{F(x) - F(a)}{F(b) - F(a)} & a \leq x \leq b\\ 0 & \text{if} \; b < x\\ \end{cases} \]
This leads to a straight forward algorithm for generating from \(F^{*}(x)\) as follows:
2. \(W = F(a) + (F(b) - F(a))u\)
3. \(X = F^{-1}(W)\)
4. return \(X\)
To implement this algorithm, we need the original CDF \(F(x)\), its range, and the truncated range \([a,b]\).
Example 2.14 (Truncated Distribution) Suppose \(X\) represents the distance between two cracks in highway. Suppose that \(X\) has an exponential distribution with a mean of 10 meters. Generate 5 random distance values restricted between 3 and 6 meters.
Note that the first line defines a distribution and not a random variable. The exponential distribution has range \([0,+\infty]\). In this situation, we are truncating the distribution over the range \([a=3, b=6]\). The TruncatedRV class implements the aforementioned algorithm. The class requires an invertible CDF, the original range of the CDF, and the truncated range. In the code, an instance of an exponential distribution (see Section 2.3) is created to provide the cumulative distribution function, \(F(x)\). This allows the implementation to compute \(F(a)\) and \(F(b)\). Then, instances of the Interval class are used to define the original range and the truncated range. As we can see from the following results, the values are limited to the range of \([3,6]\).
n Values
1 3.334730
2 3.861643
3 3.835288
4 5.408551
5 3.591583 Appendix A also defines a shifted random variable. Suppose \(X\) has a given
distribution \(f(x)\), then the distribution of \(X + \delta\) is termed the
shifted distribution and is specified by \(g(x)=f(x - \delta)\). It is
easy to generate from a shifted distribution, simply generate \(X\)
according to \(F(x)\) and then add \(\delta\). The KSL implements this idea via the ShiftedRV class. The following example from Appendix A illustrates how simple it is to use a shifted random variable.
Example 2.15 (Shifted Random Variable) Suppose \(X\) represents the time to setup a machine for production. From past time studies, we know that it cannot take any less than 5.5 minutes to prepare for the setup and that the time after the 5.5 minutes is random with a Weibull distribution with shape parameter \(\alpha = 3\) and scale parameter \(\beta = 5\). Generate 5 random observations of the setup time.
Notice that the ShiftedRV class requires the shift parameter and the random variable that is to be shifted.
This next example is a bit more complex. Recall from Appendix A that the acceptance/rejection algorithm is a general purpose method for generating from any probability distribution, \(f(x)\). The method requires a majorizing function, \(g(x)\), such that \(g(x) \geq f(x)\) for \(-\infty < x < +\infty\). From the majorizing function, we compute its area:
\[ c = \int\limits_{-\infty}^{+\infty} g(x) dx \]
We then define \(c\) as the majorizing constant. Using the majorizing constant and majorizing function, we can define a proposal distribution, \(w(x)\), where \(w(x)\) is defined as \(w(x) = g(x)/c\). To summarize, the acceptance/rejection algorithm requires three things:
- \(f(x)\) The PDF from which random variates need to be generated.
- \(w(x)\) The proposal distribution to generate possible variates for acceptance or rejection.
- \(c\) The majorizing constant (or area under the majorizing function) to be used in the acceptance/rejection test.
The AcceptanceRejectionRV class implements the acceptance/rejection algorithm given these three components. Let’s explore these concepts via an example.
Example 2.16 (Acceptance-Rejection Random Variable) Consider the following PDF over the range \(\left[-1,1\right]\). Generate 1000 random variates from this distribution. \[ f(x) = \begin{cases} \frac{3}{4}\left( 1 - x^2 \right) & -1 \leq x \leq 1\\ 0 & \text{otherwise}\\ \end{cases} \]
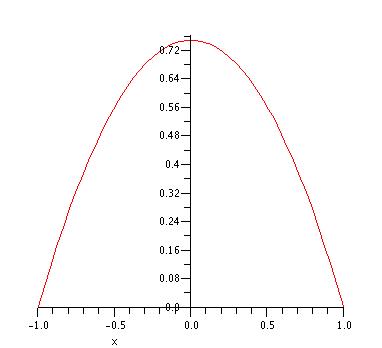
Figure 2.4: Plot of f(x)
As discussed in Example A.8 of Appendix A, we can use \(g(x) = 3/4\) as the majorizing function, which results in \(c=3/2\), and \(w(x)\)
\[
w(x) =
\begin{cases}
\frac{1}{2} & -1 \leq x \leq 1\\
0 & \text{otherwise}\\
\end{cases}
\]
Notice that, \(w(x)\) results in random variables, \(W\), where \(W \sim U(-1,1)\). Thus, the proposal distribution is simply a uniform distribution over the range from -1 to 1. The following KSL code implements these concepts. The proposal distribution, \(w(x)\) is provided via an instance of the Uniform distribution class. Probability distributions are discussed in Section 2.3. The AcceptanceRejection class then is created and used to generate 1000 observations.
fun main() {
// proposal distribution
val wx = Uniform(-1.0, 1.0)
// majorizing constant, if g(x) is majorizing function, then g(x) = w(x)*c
val c = 3.0 / 2.0
val rv = AcceptanceRejectionRV(wx, c, fOfx, streamNum = 1)
val h = Histogram.create(-1.0, 1.0, 100)
for (i in 1..1000) {
h.collect(rv.value)
}
println(h)
val hp = h.histogramPlot()
hp.showInBrowser()
val dp = DensityPlot(h) { x -> fOfx.pdf(x) }
dp.showInBrowser()
}
object fOfx : PDFIfc {
override fun pdf(x: Double): Double {
if ((x < -1.0) || (x > 1))
return 0.0
return (0.75 * (1.0 - x * x))
}
override fun domain(): Interval {
return Interval(-1.0, 1.0)
}
}Notice that the implementation requires an implementation of the PDF from which random variates are to be generated, \(f(x)\). The fOfx object is used to implement the function and its domain. The code also illustrates how to create a histogram of the observations. Histograms are discussed further in Section 3.1.2 of Chapter 3.
In what follows, we briefly describe some additional functionality of the KSL for generating random variates and for applying randomness to arrays and lists.
The preferred method for generating random values from random
variables is to create an instance of the appropriate random variable
class; however, the KSL also provides a set of functions for generating random
values within the KSLRandom object. For all the previously listed random variables, there is a
corresponding function that will generate a random value. For
example, the function rNormal() of the KSLRandom object will generate a normally distributed
value. Each function is named with an "r" in front of the distribution
name. By using an import of KSLRandom functions the user can more conveniently call these methods. The following code example illustrates how to do this.
Example 2.17 (Using KSLRandom Functions) The functions require the specification of the parameters of the distribution for each invocation.
In addition to random values through these functions, the
KSLRandom object provides a set of methods for randomly selecting from
arrays and lists and for creating permutations of arrays and lists. In
addition, there is a set of methods for sampling from arrays and lists
without replacement. The following code provides examples of using these methods.
Example 2.18 (Random Lists) The randomlySelect() function can be used to randomly select, with equal probability from a Kotlin list. An extension function has been defined to allow this to be done directly from the list.
It is also possible to specify a distribution in the form of a CDF array over the items in the list to permit sampling that is not equally likely. There are also extension functions declared on arrays for directly performing this form of random selection.
This next example illustrates how to define a population of values via the DPopulation class and to use it to perform sampling operations such as random samples and permutations. Similar functionality is also demonstrated by directly using the functions of the KSLRandom object
Example 2.19 (Random Permuation) This example defines a population over the integer from 1 to 10 and permutes the population. It also illustrates how to sample from the population and permute a mutable list.
fun main() {
// create an array to hold a population of values
val y = DoubleArray(10)
for (i in 0..9) {
y[i] = (i + 1).toDouble()
}
// create the population
val p = DPopulation(y, streamNum = 1)
println(p.contentToString())
println("Print the permuted population")
// permute the population
p.permute()
println(p.contentToString())
// directly permute the array using KSLRandom
println("Permuting y")
KSLRandom.permute(y)
println(y.contentToString())
// sample from the population
val x = p.sample(5)
println("Sampling 5 from the population")
println(x.contentToString())
// create a string list and permute it
val strList: MutableList<String> = ArrayList()
strList.add("a")
strList.add("b")
strList.add("c")
strList.add("d")
println("The mutable list")
println(strList)
KSLRandom.permute(strList)
println("The permuted list")
println(strList)
println("Permute using extension function")
strList.permute()
println(strList)
}Output from the permutation examples.
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
Print the permuted population
[2.0, 4.0, 5.0, 9.0, 6.0, 8.0, 3.0, 1.0, 7.0, 10.0]
Permuting y
[6.0, 5.0, 2.0, 3.0, 8.0, 10.0, 4.0, 7.0, 1.0, 9.0]
Sampling 5 from the population
[1.0, 4.0, 2.0, 5.0, 3.0]
The mutable list
[a, b, c, d]
The permuted list
[a, c, b, d]
Permute using extension function
[d, a, c, b]2.2.4 Functions of Random Variables
The KSL also contains an algebra for working with random variables. A well-known property of random variables is that a function of a random variable is also a random variable. That is, let \(f(\cdot)\) be an arbitrary function and let \(X\) be a random variable. Then, the quantity \(Y = f(X)\) is also a random variable. Various properties of \(Y\) such as expectation, \(E[Y]\) and \(Var[Y]\) may be of interest. A classic example of this is the relationship between the normal random variable and the lognormal random variable. If \(X \sim N(\mu, \sigma^2)\) then the random variable \(Y=e^X\) will be lognormally distributed \(LN(\mu_l,\sigma_{l}^{2})\), where
\[\begin{equation} E[Y] = \mu_l = e^{\mu + \sigma^{2}/2} \end{equation}\]
\[\begin{equation} Var[Y] = \sigma_{l}^{2} = e^{2\mu + \sigma^{2}}\left(e^{\sigma^{2}} - 1\right) \end{equation}\]
Thus, one can define new random variables simply as functions of other random variables.
The interface RVariableIfc and base class RVariable provides the ability to construct new random variables that are functions of other random variables by overriding the \((+, -, \times, \div)\) operators and providing extension functions for various math functions. For example, we can defined two random variables and then a third that is the sum of the first two random variables. The random variable that is defined as the sum will generate random variates that represent the sum. Functions, such as sin(), cos() as well as many other standard math functions can be applied to random variables to create new random variables. That is, the KSL provides the ability to create arbitrarily complex random variables that are defined as functions of other random variables. This capability will be illustrated in this section with a couple of examples.
Example 2.20 (Erlang Via Convolution) Suppose we have \(k\) independent random variables, \(X_i\) each exponentially distributed with mean \(\theta\). Then, the random variable: \[\begin{equation} Y = \sum_{i=i}^{k}X_i \end{equation}\] will be an Erlang\((k, \theta)\) where \(k\) is the shape parameter and \(\theta\) is the scale parameter. Set up a KSL model to generate 1000 Erlang random variables with \(k = 5\) and \(\theta = 10\).
A possible solution to this problem is to use the KSL to define a new random variable that is the sum of 5 exponential random variables.
fun main(){
var erlang: RVariableIfc = ExponentialRV(10.0, streamNum = 1)
for(i in 1..4) {
erlang = erlang + ExponentialRV(10.0)
}
println("stream number = ${erlang.streamNumber}")
val sample = erlang.sample(1000)
val stats = Statistic(sample)
println()
print(stats)
sample.writeToFile("erlang.txt")
}The first line of this code creates and stores an instance of an exponential random variable with mean 10. The for loop is not generating any random variates. It is defining a new random variable that is the sum of 4 additional exponential random variables. The defined random variable is used to generate a sample of size 1000 and using the Statistic class (discussed in the next chapter) a basic statistical summary is computed. Also, using the writeToFile KSL extension function for double arrays, the sample is written to a file. The results as a histogram are also presented. The statistical results are as follows.
stream number = 1
ID 31
Name Statistic_1
Number 1000.0
Average 50.22504832196012
Standard Deviation 22.130436282067713
Standard Error 0.699825842645625
Half-width 1.3732971036698247
Confidence Level 0.95
Confidence Interval [48.85175121829029, 51.598345425629944]
Minimum 8.517383088139447
Maximum 147.81714627300153
Sum 50225.048321960116
Variance 489.75621003465903
Deviation Sum of Squares 489266.45382462436
Last value collected 32.293283161673294
Kurtosis 0.9888978451474602
Skewness 0.8816305761311749
Lag 1 Covariance -19.73716912800237
Lag 1 Correlation -0.040340327798310656
Von Neumann Lag 1 Test Statistic -1.2518042413131365
Number of missing observations 0.0
Lead-Digit Rule(1) -1
Figure 2.5: Histogram for Erlang Generated Data
Notice that the histogram looks like an Erlang distribution and the estimated results are what we would expect for an Erlang distribution with \(k=5\) and \(\theta = 10\).
To illustrate a couple of other examples consider the following code. In this code, the previously noted relationship between normal random variables and lognormal random variables is demonstrated in the first 6 lines of the code.
Example 2.21 (Functions of Random Variables) This example uses the fact that if \(X \sim N(\mu,\sigma^2)\), then \(Y = e^{X} \sim \text{LN}(\mu_l,\sigma_{l}^{2})\). In addition, the code illustrates how to generate a beta random variable via its relationship with gamma random variables. The assignment of streams is a bit more complex for functions of random variables. Notice that in the following code, the random variable (normal in the first case) is assigned stream number 1. This stream is then used by all of the transformations. In the example of generating a beta random variable, the first random variable, y1 has stream 2. The random variable y2 has the next stream number (3); however, because the denominator has y1 + y2 and y1 appears first in the functional transformation, the resulting random variable y1 + y2 will have stream 2. Then, when y1 is divided by y1 + y2, the resulting random variable betaRV will use stream 2. Thus, the order of operation is important in the determination of the resulting assigned stream.
fun main(){
// define a lognormal random variable, y
val x = NormalRV(2.0, 5.0, streamNum = 1)
val y = exp(x)
// generate from y
println("stream number = ${y.streamNumber}")
val ySample = y.sample(1000)
println(ySample.statistics())
// define a beta random variable in terms of gamma
val alpha1 = 2.0
val alpha2 = 5.0
val y1 = GammaRV(alpha1, 1.0, streamNum = 2)
val y2 = GammaRV(alpha2, 1.0)
val betaRV = y1/(y1+y2)
val betaSample = betaRV.sample(500)
println("stream number = ${betaRV.streamNumber}")
println(betaSample.statistics())
}One method for generating Beta random variables exploits its relationship with the Gamma distribution. If \(Y_1 \sim Gamma(\alpha_1, 1)\) and \(Y_2 \sim Gamma(\alpha_2, 1)\), then \(X = Y_1/(Y_1 + Y_2)\) has a Beta(\(\alpha_1, \alpha_2\)) distribution. In the previous KSL code, we defined two gamma random variables and define the beta random variable using the algebraic expression. This code defines and constructs a new random variable that is function of the previously defined random variables. Through this pattern you can define complex random variables and use those random variables anywhere that a random variable is needed.