9.2 Variance Reduction Techniques
A variance reduction technique (VRT) represents a sampling strategy that has the overall goal of finding an estimator that will have lower variance than the typical estimator based on straightforward random sampling. The objective of a VRT is to reduce the theoretical population variance of the sampling distribution associated with an estimator \(\hat{\theta}\), of some population parameter \(\theta\). For example, in many instances, we are interested in the population mean, \(\theta\), and thus the standard estimator that is proposed is the sample mean \(\hat{\theta} = \bar{Y}\). Suppose we have the following IID observations \((Y_1, Y_2, \cdots, Y_n)\) with \(E[Y_i]=\theta\) and \(\text{Var}[Y_i] = \sigma^{2}_{Y}\). Then the standard (or so called crude) estimator for \(\theta\) is \(\bar{Y}\) and the variance of the estimator is
\[ \text{Var}[\bar{Y}]=\text{Var}\bigg[\frac{1}{n}\sum_{i=1}^{n}Y_i \bigg] = \frac{1}{n^2}\sum_{i=1}^{n}\text{Var}[Y_i]=\frac{n \,\text{Var}[Y_i]}{n^2} = \frac{\text{Var}[Y_i]}{n}=\frac{\sigma^2_{Y}}{n} \]
When applying a VRT, the goal is to do better than \(\text{Var}[\bar{Y}]\). While it may be obvious, it is worth stating that the simplest variance reduction technique is to use a larger sample. Consider estimating the population mean, \(\theta\) based on a random sample using:
\[ \bar{Y}(n) = \frac{1}{n}\sum_{i=1}^{n}Y_i \] Here, we have emphasized that the estimator, \(\bar{Y}(n)\) is a function of the sample size, \(n\). So consider two estimators, \(\hat{\theta}_1 = \bar{Y}(n_1)\) and \(\hat{\theta}_2 =\bar{Y}(n_2)\) where \(n_1 < n_2\). Thus, we will have that:
\[ \text{Var}[\bar{Y}(n_1)] = \text{Var}[\hat{\theta}_1] = \frac{\sigma^2_{Y}}{n_1} \]
and,
\[ \text{Var}[\bar{Y}(n_2)] = \text{Var}[\hat{\theta}_2] = \frac{\sigma^2_{Y}}{n_2} \] and thus because \(n_1 < n_2\), we have that \(\text{Var}[\bar{Y}(n_2)] < \text{Var}[\bar{Y}(n_1)]\). Thus, we have two estimators \(\hat{\theta}_1\) and \(\hat{\theta}_2\) where the variance of one estimator is smaller than the variance of another. In this particular case, both of the estimators are unbiased, and not considering the extra time that may be required to sample the larger sample, we would prefer the estimator \(\hat{\theta}_2\) over the estimator \(\hat{\theta}_1\) because \(\hat{\theta}_2\) has lower variance. That is, the variance of its sampling distribution is lower. As noted, we have to ignore the possible extra computation time needed for \(\hat{\theta}_2\). In what follows, we will generally ignore computational issues, and in most of the VRT methods that will be presented, the assumption will be very reasonable. However, there is also the effort needed to implement a more “complicated” sampling method than straightforward random sampling. In some modeling situations, this extra implementation effort should not be ignored when considering the possible use of a VRT.
The important thing to remember is that the variance reduction refers to reducing the population variance of the estimator of \(\theta\). The parameter of interest does not have to be the mean. The parameter \(\theta\) can be any parameter of the underlying population. For example, we might try to estimate the median, quantile, or the population variance \(\sigma^{2}_{Y}\). One important point to remember, variance reduction methods do not affect the variability of the process (population). That is \(\sigma^{2}_{Y}\) does not change. When applying a VRT, we are changing the variance associated with the sampling distribution of the estimator, \(\hat{\theta}\).
The major types of variance reduction techniques to be discussed in this section, include:
- Manipulating randomness
- Common Random Numbers (CRN)
- Antithetic Variates (AV)
- Exploiting process knowledge
- Indirect Estimation (IE)
- Control Variates (CV)
- Stratified and Post Stratified Sampling (PS)
- Conditional Expectation (CE)
- Importance Sampling (IS)
Manipulating randomness refers to the judicious use of the random number streams. Exploiting process knowledge refers to the general intuition that more information reduces uncertainty.
9.2.1 Common Random Numbers (CRN)
In Section 5.7.1.2, we already discussed the use of common random numbers when comparing two systems. Here we will review the key results and mention a couple of implementation issues.
CRN exploits the idea that if each alternative experiences the same randomness, then the difference between the two alternatives will be because of a true underlying difference, rather than because of the randomness. Define \(\theta = \theta_1 - \theta_2\) as the parameter of interest, and define \(D_i = X_i - Y_i\) as the difference between the \(i^{th}\) pairs of performance observations, for \(i=1,2, \cdots, n\), where \(n\) is the number of observations. The point estimator is \(\hat{\theta} = \bar{D} = \bar{X} - \bar{Y}\), with interval estimator:
\[ \bar{D} \pm t_{1-\alpha/2,n-1}\frac{s_D}{\sqrt{n}} \]
By considering the variance of \(\bar{D} = \bar{X} - \bar{Y}\), we have that,
\[ \text{Var}[\bar{D}]=\frac{\text{Var}[D_i]}{n}=\frac{1}{n}\text{Var}[X_i - Y_i]=\frac{1}{n}\Bigg[\text{Var}[X_i]+\text{Var}[Y_i]-2\text{cov}[X_i,Y_i] \Bigg] \]
And, therefore,
\[ \text{Var}[\bar{D}]=\frac{\sigma^{2}_{X}}{n} +\frac{\sigma^{2}_{Y}}{n} - 2\rho_{XY}\sigma_{X}\sigma_{Y} \]
If the random variables \(X\) and \(Y\) are independent, then \(\rho_{XY}= 0\) and: \[ V_{IND} = \text{Var}[\bar{D}]=\frac{\sigma^{2}_{X}}{n} +\frac{\sigma^{2}_{Y}}{n} \]
In analyzing the worth of a VRT, we will need to derive the variance of the estimator. Thus, deriving the variance for the CRN and the independent (IND) estimators, we have:
\[ V_{CRN} = V_{IND} - 2\rho_{XY}\sigma_{X}\sigma_{Y} \]
\[ V_{IND} - V_{CRN} = 2\rho_{XY}\sigma_{X}\sigma_{Y} \]
This implies that if there is positive correlation between \(X\) and \(Y\), \(\rho_{XY} \ge 0\), we will have:
\[ V_{IND} - V_{CRN} \ge 0 \]
\[ V_{CRN} \le V_{IND} \]
Therefore, the variance of the CRN estimator should be smaller than the variance of the crude estimator if there is positive correlation. If we can induce a positive correlation within the pairs \((X_i, Y_i)\), then when we use
\[ \hat{\theta} = \frac{1}{n}\sum_{i=1}^{n}D_i = \frac{1}{n}\sum_{i=1}^{n}(X_i - Y_i) \]
we will have a variance reduction (a more precise estimate). It is important to note that the sampling distribution of \(\hat{\theta}\) is different because the pairs \((X_i, Y_i)\) were sampled in a dependent manner.
So, CRN will work when we can induce a positive correlation within the pairs \((X_i, Y_i)\) and it will backfire (cause an increase in the variance) if there is a negative correlation within the pairs \((X_i, Y_i)\). In the case of simple Monte Carlo, it should be clear that we can induce positive correlation between \(X_i\) and \(Y_i\) by using the same random numbers during the generation process. Suppose \(X_i \sim F_{X}(x)\) and \(Y_i \sim F_{Y}(y)\) and we have the inverse transform functions for \(F_X\) and \(F_Y\). Then, to generate \(X_i\) and \(Y_i\) we use:
\[ U_i \sim U(0,1)\\ X_i = F_{X}^{-1}(U_i)\\ Y_i = F_{Y}^{-1}(U_i)\\ \] Thus, if \(U_i\) is large, then because the inverse CDF, \(F^{-1}(p)\) is a monotone function, \(X_i\) will be large and \(Y_i\) will be large. In addition, if \(U_i\) is small, then \(X_i\) will be small and \(Y_i\) will be small. Thus, there will be positive correlation. In this simple case of \(D_i = X_i - Y_i\) the monotone relationship will be maintained; however, in a general discrete event dynamic simulation modeling context, the situation is much more complex.
For example, suppose we are estimating the waiting time in bank open from 9 am to 5 pm, \(\theta\). Here we have an arrival distribution, \(F_A(x)\), and a service distribution, \(F_S(x)\), and the number of tellers that govern the underlying stochastic processes. Suppose we want to compare the performance (in terms of the average waiting time) for system 1, \(\theta_1\) to the average waiting time for system 2, \(\theta_2\), where the arrival rate of system 1, \(\lambda_1\) is higher than the arrival rate for system 2, \(\lambda_2\) and the service distributions remain the same, as well as the number of tellers.
Now, suspending our analytical thinking about which system actually should have the higher waiting time, we run simulation experiments to compare, \(\hat{\theta}_1\) to \(\hat{\theta}_2\). Assuming that we run two experiments, each with \(r\) as the number of replications, and \(m_{r}^{i}\) as the number of observed customers in replication \(r\) for system \(i\), where \(W_{kj}^{i}\) is the observed waiting time for system \(i\) for customer \(k\) in replication \(j\), we have that our estimators of performance for \(i=1, 2\) to be:
\[ \hat{\theta}_i = \frac{1}{r}\sum_{j=1}^{r}\bar{W}_{j}^{i} \]
where,
\[ \bar{W}_{j}^{i} = \frac{1}{m_{j}^{i}}\sum_{k=1}^{m_{j}^{i}} W_{kj}^{i} \]
Notice that the number of observations for each system \(i\), \(m_{j}^{i}\) for each replication \(j\) can vary by the system being considered and the number of observations within each replication \(j\) can be different. Thus, the differences are \(D_j = \bar{W}_{j}^{1} - \bar{W}_{j}^{2}\) for \(j = 1, 2, \cdots, r\) and \(\bar{D} = \hat{\theta}_1 - \hat{\theta}_2\) is our estimator of the difference between system 1 and system 2.
For CRN to work, we need to induce a positive correlation within the pairs \((\bar{W}_{j}^{1}, \bar{W}_{j}^{2})\) for \(j = 1, 2, \cdots, r\). How can we possibly do that using common random numbers? Note that we are not directly generating \(\bar{W}_{j}^{i}\) using an inverse cumulative distribution function as in the previously discussed simple case of \(D_i = X_i - Y_i\). The random variables \(\bar{W}_{j}^{i}\) are obtained from averaging the observed waiting times, \(W_{kj}^{i}\), for system \(i\) for the \(k = 1, 2, \cdots,m_{j}^{i}\) customers in replication \(j\). Also, note that we are not directly generating (via inverse transform functions) the waiting time observations for each customer, \(W_{kj}^{i}\).
Focusing on a single replication with subscript \(j\), let’s consider how the random numbers are used within the replication. Let \(A_{kj}\) be the \(k^{th}\) inter-arrival time, where \(a_{1j}\) is the realized inter-arrival time of the first customer, and so forth on the \(j^{th}\) replication. Let \(S_{kj}\) be the service time of the \(k^{th}\) customer, where \(s_{1j}\) is the realized service time of the first customer, and so forth on the \(j^{th}\) replication. Assume that we use the inverse transform technique for generating \(A_{kj}\) and \(S_{kj}\), such that the \(k^{th}\) customer’s inter-arrival and service times are governed by \(a_{kj} = F_{A}^{-1}(u_{kj})\) and \(s_{kj} = F_S^{-1}(v_{kj})\), where \(U_{kj} \sim U(0,1)\) and \(V_{kj} \sim U(0,1)\) resulting in realizations, \(u_{kj}\) and \(v_{kj}\). Note that in what follows I have denoted \(m_{j}^{1}\) with subscript \(j\) to denote the\(j^{th}\) replication and with superscript \(1\) to denote system 1.
\[ u_{1j}, u_{2j}, u_{3j}, \cdots, u_{m_{j}^{1}j} \\ a_{1j}, a_{2j}, a_{3j}, \cdots, a_{m_{j}^{1}j} \\ v_{1j}, v_{2j}, v_{3j}, \cdots, v_{m_{j}^{1}j} \\ s_{1j}, s_{2j}, s_{3j}, \cdots, s_{m_{j}^{1}j} \\ \vdots \\ \downarrow \\ w_{1j}, w_{2j}, w_{3j}, \cdots, w_{m_{j}^{1}j} \rightarrow \bar{w}_{j}^{1} \] Given values for \(a_{kj}\) and \(s_{kj}\), we can execute the event logic and produce observations of \(w_{kj}^{i}\) of the waiting times for the \(m_{j}^{i}\) customers within each replication \(j\) for system \(1\). Notice that the pseudo random numbers for the first customer, \((u_{1j}, v_{1j})\) are used to produced the inter-arrival time and service time for the first customer, \((a_{1j} = F_{A^{1}}^{-1}(u_{1j}), s_{1j} = F_{S^{1}}^{-1}(v_{1j}))\), which then produces the waiting time for the first customer, \(w_{1j}\). That is, \((u_{1j}, v_{1j}) \rightarrow (a_{1j}, s_{1j}) \rightarrow w_{1j}\). Here \(A^{1}\) and \(S^{1}\) denote the arrival and service time distributions for system \(1\).
Now, consider the simulation of system 2.
\[ u_{1j}, u_{2j}, u_{3j}, \cdots, u_{m_{j}^{2}j} \\ a_{1j}, a_{2j}, a_{3j}, \cdots, a_{m_{j}^{2}j} \\ v_{1j}, v_{2j}, v_{3j}, \cdots, v_{m_{j}^{2}j} \\ s_{1j}, s_{2j}, s_{3j}, \cdots, s_{m_{j}^{2}j} \\ \vdots \\ \downarrow \\ w_{1j}, w_{2j}, w_{3j}, \cdots, w_{m_{j}^{2}j} \rightarrow \bar{w}_{j}^{2} \] When using common random numbers the same sequences of pseudo-random numbers \((u_{1j}, u_{2j}, u_{3j}, \cdots, u_{m_{j}^{i}j})\) and \((v_{1j}, v_{2j}, v_{3j}, \cdots, v_{m_{j}^{i}j})\) will be used for each replication of system \(i\). This will not imply that the same inter-arrival and service time values, \((a_{1j}, s_{1j})\), will be used in the two experiments because inter-arrival distribution for system 1, \(F_{A^1}\), is not the same as the inter-arrival distribution for system 2, \(F_{A^2}\), because the arrival rate of system 1 \((\lambda_1)\) is bigger than the arrival rate of system 2, \((\lambda_2)\). However, it should be clear that the inter-arrival times for the two systems will be correlated because a large \(u_{1j}\) will produce a large \(a^{1}_{1j}\) for system 1 and a large \(a^{2}_{1j}\) for system 2. In addition, because the same \((v_{1j}, v_{2j}, v_{3j}, \cdots, v_{m_{j}^{i}j})\) will be used and the service time distributions are the same for system 1 and system 2, the same service times will be used for each customer. That is, each customer will experience exactly the same service time when executing the experiments for system 1 and system 2. These insights should suggest to you that correlation will be induced between pairs \((\bar{W}_{j}^{1}, \bar{W}_{j}^{2})\) and thus a variance reduction is likely. Note that system 1 will use more pseudo random numbers \((u_{1j}, u_{2j}, u_{3j}, \cdots)\) than system 2 because system one’s arrival rate is higher than system two’s arrival rate, thereby, causing \(m_{j}^{1} > m_{j}^{2}\) for \(j=1, 2, \cdots, r\).
A best practice for inducing correlation is to try to synchronize the use of the pseudo-random numbers when executing the simulation experiments. Best practices for synchronization include:
Utilize the inverse transform technique to generate random variates. The KSL does this by default. Methods such as acceptance/rejection do not have a one-to-one mapping between \(U_i\) and \(X_i\). A one-to-one mapping occurs by default for the inverse transform technique.
Dedicate a different stream to each underlying source of randomness within the model. The KSL does this automatically.
Dedicate all the random variates to be used by an entity when the entity is created and store them in attributes for when they are needed. This may be impractical due to storage/memory issues or it may be impossible to know in advance if the attribute will be needed. In addition, in general, it takes extra effort to implement this approach in most simulation packages.
If unable to fully synchronize, then you should try to ensure that the random variables that cannot be synchronized are independent (i.e. use different streams).
Make sure that each replication (sample path) starts in the same place for each synchronized random number stream. The KSL does this automatically by advancing to the next sub-stream of the current stream for each random variable at the beginning of each replication. This ensures that at the beginning of each replication, the same pseudo-random numbers are used.
CRN should work if the performance measure of interest for the alternatives is monotonic (in the same direction for the systems) for the random number stream. A large value of the random variable that causes \(\hat{\theta}_{1}\) to go up will also cause \(\hat{\theta}_{2}\) to go up. Or, a large value of the random variable that causes \(\hat{\theta}_{1}\) to go down will also cause \(\hat{\theta}_{2}\) to go down. In addition, a small value of the random variable causes \(\hat{\theta}_{1}\) to go up will also cause \(\hat{\theta}_{2}\) to go up. Or, a small value of the random variable that causes \(\hat{\theta}_{1}\) to go down will also cause \(\hat{\theta}_{2}\) to go down. These rules are about inducing positive correlation. If negative correlation occurs, then the variance will be inflated. The good news is that you can always check for negative correlation and not utilize CRN if negative correlation is being observed. Because you are likely to run some small pilot runs to plan the experiments (e.g. sample size), I recommend using those pilot runs to also check if CRN is working as intended. Almost all modern simulation languages facilitate simulation using common random numbers by allowing the user to specify streams.
9.2.2 Antithetic Variates (AV)
Antithetic variates is a class of variance reduction technique that utilizes the manipulation of the underlying random number streams to change the sampling distribution. In contrast to CRN, antithetic variates is applicable to the reduction of variance for estimators from a single simulation experiment (single system). In antithetic variates, we attempt to induce correlation between the (executions or runs) of the simulation. Suppose that we can generate observations of our performance measure \((Y_1, Y_2, \cdots, Y_n)\) where \(Y_i\) is the observed performance of on run \(i\) of the simulation. Here the observations \((Y_1, Y_2, \cdots, Y_n)\) are not assumed to be independent. Thus, we call them runs rather than replications.
Assume that we have a covariance stationary process with \((Y_1, Y_2, \cdots, Y_n)\) with \(E[Y_i]=\theta\) and \(var[Y_i] = \sigma^{2}_{Y}\). We can derive the variance of \(\bar{Y}\) as follows:
\[ \text{Var}\left[\bar{Y}\right] = \dfrac{\sigma^2_Y}{n} \Bigg[1 + 2\sum_{j=1}^{n-1} \Bigg(1 - \dfrac{j}{n}\Bigg) \rho_j \Bigg] \]
where \[\rho_j = \frac{cov(Y_i, Y_{i+j})}{\sigma^2_Y}\]
Thus, if we can induce negative correlation, then the \(\text{Var}\left[\bar{Y}\right]\) can be reduced. The trick is to try to induce negative correlation and still be able to form valid confidence intervals. To do this we induce correlation within pairs \((Y_i, Y_{i+1})\) by manipulating the random number streams.
Let \(n\) be the sample size and ensure that \(n\) is even. Consider the sequence of pairs, \((Y_{2j-1}, Y_{2j})\) for \(j=1,2,\cdots, (n/2)\) where the random variables within a pair are dependent but they are independent across the pairs. With \(m = n/2\), define the AV estimator as:
\[ \hat{Y} = \frac{1}{m}\sum_{j=1}^{m}\frac{Y_{2j-1} + Y_{2j}}{2}=\frac{1}{m}\sum_{j=1}^{m}\hat{Y_j}= \bar{Y} \]
where
\[ \hat{Y_j} =\frac{Y_{2j-1} + Y_{2j}}{2} \]
The variance of \(\hat{Y}\) is reduced by inducing a negative correlation within pairs \((Y_i, Y_{i+1})\). Confidence intervals can be computed by treating the sequence \((\hat{Y_1}, \hat{Y_2}, \cdots, \hat{Y_m})\) as a random sample of size \(m\) and applying confidence interval methods.
Let’s take a look at how AV works. Consider the \(var[\hat{Y}]\) \[ \text{Var}[\hat{Y}] = \frac{\text{Var}(\hat{Y_j})}{m}=\frac{1}{m}\Bigg[ \text{Var}\Bigg( \frac{Y_{2j-1} + Y_{2j}}{2}\Bigg) \Bigg]=\frac{1}{4m}\Bigg[ \text{Var}[Y_{2j-1}]+ \text{Var}[Y_{2j}]+2cov[Y_{2j-1},Y_{2j}]\Bigg] \]
Since the process is covariance stationary \(\text{Var}[Y_{2j-1}] = \text{Var}[Y_{2j}] = \sigma^2_Y\). Thus,
\[ \text{Var}[\hat{Y_j}] =\frac{1}{4}\Bigg[ \sigma^2_Y + \sigma^2_Y+2\sigma^2_Y \rho\Bigg]=\frac{\sigma^2_Y}{2}(1+\rho) \] where the correlation is defined as:
\[ \rho = corr(Y_{2j-1}, Y_{2j}) = \frac{cov(Y_{2j-1}, Y_{2j})}{\sigma^2_Y} \]
Because
\[ \text{Var}[\hat{Y_j}] =\frac{1}{4}\Bigg[ \sigma^2_Y + \sigma^2_Y+2\sigma^2_Y \rho\Bigg]=\frac{\sigma^2_Y}{2}(1+\rho) \]
we have
\[ \text{Var}[\hat{Y}]=\frac{\sigma^2_Y}{2m}(1+\rho)=\frac{\sigma^2_Y}{n}(1+\rho) \]
Therefore, if \(\rho < 0\), then \(\text{Var}[\hat{Y}] < \frac{\sigma^2_Y}{n}\). This implies a variance reduction that is directly proportional to the amount of negative correlation that can be induced within the pairs.
To implement antithetic variates, we can consider the following recipe:
- Each simulation run (like a replication) use random number streams such that alternating runs use antithetic streams.
- Run 1: \((u_1, u_2, \cdots, u_k)\)
- Run 2: \((1-u_1, 1-u_2, \cdots, 1-u_k)\)
- Run 3: \((u_{k+1}, u_{k+2}, \cdots, u_{2k})\)
- Run 4: \((1-u_{k+1}, 1-u_{k+2}, \cdots, 1-u_{2k})\), etc.
- Each stream is mapped to some distribution, \(F(x)\) in the model, then, suppose,\(X_{2j-1}\) and \(X_{2j}\) are inputs on runs \(2j-1\) and \(2j\), where \(j=1,2,\cdots,m\). Then, if the inverse transform method is used we have \(X_{2j-1}=F^{-1}(u)\) and \(X_{2j}=F^{-1}(1-u)\).
If the underlying random variables map to outputs monotonically, similar to the CRN situation, then the negative correlation may be preserved within the pairs for the simulation performance measures, which will cause a variance reduction. Just like in CRN, synchronization is important and the same best practices are recommended.
An example of how to perform an antithetic experiment within a Monte Carlo context was presented in 2.1.4. Within a simple Monte Carlo context the implementation of antithetic variates is relatively straight-forward. Reviewing the implementation of the class MC1DIntegration within the ksl.utilities.mcintegration package is illustrative of the basic approach. The MC1DIntegration class provides for the use of antithetic variates when estimating the area of a 1-dimensional function. In the following Kotlin code, we see that in the init block if the antitheticOption is true an antithetic instance is created from the random variable used in the sampling.
class MC1DIntegration (
function: FunctionIfc,
sampler: RVariableIfc,
antitheticOption: Boolean = true
) : MCExperiment() {
protected val myFunction: FunctionIfc
protected val mySampler: RVariableIfc
protected var myAntitheticSampler: RVariableIfc? = null
init {
myFunction = function
mySampler = sampler
if (antitheticOption){
myAntitheticSampler = sampler.antitheticInstance()
}
confidenceLevel = 0.99
}Recall that the MCExperiment class, see Section 3.8, requires the user to provide an implementation of the MCReplicationIfc interface. In the MC1DIntegration class we have the following implementation.
override fun replication(j: Int): Double {
return if (isAntitheticOptionOn) {
val y1 = myFunction.f(mySampler.sample())
val y2 = myFunction.f(myAntitheticSampler!!.sample())
(y1 + y2) / 2.0
} else {
myFunction.f(mySampler.sample())
}
}Note that if the antithetic variate option is turned on, then the replication(j: Int) function returns
\[ \hat{Y_j} =\frac{Y_{2j-1} + Y_{2j}}{2} \]
by using the antithetic sampler for \(Y_{2j}\). Thus, each replication is defined as a pair of runs (antithetic off, antithetic on). This implementation uses a separate antithetic sampler; however, as shown in Section 2.1.4 the same effect can be achieved by using one stream, resetting it and turning on the antithetic option for the stream.
Implementing antithetic variates within the context of DEDS is more complicated. Similar to the discussion associated with CRN, let’s consider what happens for the pairs of runs \(2j-1\) and \(2j\).
For the \(2j-1\) run we have: \[ u_{1}, u_{2}, u_{3}, \cdots, u_{m} \\ a_{1}, a_{2}, a_{3}, \cdots, a_{m} \\ v_{1}, v_{2}, v_{3}, \cdots, v_{m} \\ s_{1}, s_{2}, s_{3}, \cdots, s_{m} \\ \vdots \\ \downarrow \\ w_{1}, w_{2}, w_{3}, \cdots, w_{m} \rightarrow \bar{w}_{2j-1} \] For the \(2j\) run we use the antithetic variates such that, \(a_{k} = F_{A}^{-1}(1-u_{k})\) and \(s_{k} = F_S^{-1}(1-v_{k})\): \[ 1-u_{1}, 1-u_{2}, 1-u_{3}, \cdots, 1-u_{m} \\ a_{1}, a_{2}, a_{3}, \cdots, a_{m} \\ 1-v_{1}, 1-v_{2}, 1-v_{3}, \cdots, 1-v_{m} \\ s_{1}, s_{2}, s_{3}, \cdots, s_{m} \\ \vdots \\ \downarrow \\ w_{1}, w_{2}, w_{3}, \cdots, w_{m} \rightarrow \bar{w}_{2j} \] This should cause the pairs \((\bar{W}_{2j-1}, \bar{W}_{2j})\) to have negative correlation. Again the actual realization of some variance reduction will depend upon synchronization strategies and responses, such as the waiting time, responding in a monotonic fashion to the antithetic sampling.
Within a DEDS context, the KSL permits the model to be executed and the streams controlled to implement antithetic sampling. The property antitheticOption of the Model class controls whether the streams use antithetic sampling. It may be instructive to see how this is implemented within the Model class.
private fun handleAntitheticReplications() {
// handle antithetic replications
if (antitheticOption) {
logger.info { "Executing handleAntitheticReplications() setup" }
if (currentReplicationNumber % 2 == 0) {
// even number replication
// return to beginning of sub-stream
resetStartSubStream()
// turn on antithetic sampling
antitheticOption(true)
} else // odd number replication
if (currentReplicationNumber > 1) {
// turn off antithetic sampling
antitheticOption(false)
// advance to next sub-stream
advanceToNextSubStream()
}
}
}In the previous code, we see that if the replication number is even (a multiple of 2), the the streams are reset to the beginning of their current sub-stream and the antithetic option is turned on for every random variable (instance of the RandomVariable class) used within the model. This causes the sampling performed during an even run to use antithetic pseudo-random numbers. Then, for odd replications, the antithetic option is turned off and the normal stream advancement occurs. Thus, within the KSL a simple change of a property permits antithetic sampling.
9.2.3 Indirect Estimation
While not as generalizable as CRN or AV, indirect estimation is interesting because it illustrates the general concept of replacing uncertainty with knowledge to reduce variance. The basic idea is to exploit an analytical relationship involving the parameter of interest with other random variables whose population values are known. The most useful application of indirect estimation has been the use of Little’s formula or other conservation law relationships for simulations involving queueuing.
Suppose we are interested in estimating \(W_q\), \(W_s\), \(L_q\), and \(L_s\) in a GI/G/c queueing simulation. Little’s formulat tells us that \(L_s = \lambda W_s\),\(L_q = \lambda W_q\), and \(B = L_s - L_q = \lambda E[ST]\), where \(E[ST]\) is the mean of the service time distribution and \(\lambda\) is the mean arrival rate. We also know that \(W_s = W_q + E[ST]\). During the simulation, we can directly observe the waiting time \(W_{q_i}\) of each customer in the queue and estimate \(W_q\) with:
\[ \hat{W}_q = \frac{1}{n}\sum_{i=1}^{n}W_{q_i} \]
Indirect estimation suggests that we estimate the other performance measures using the operational relationships.
- \(\hat{W}_s = \hat{W}_q + E[ST]\)
- \(\hat{L}_q = \lambda \hat{W}_q\), and
- \(\hat{L}_s = \lambda (\hat{W}_q + E[ST])\)
Notice that known quantities \(E[ST]\) and \(\lambda\) are used. This replaces variability with certainty causing a variance reduction. Experimental studies have shown that this approach will work well provided that the operational formulas are applicable. However, this approach requires the implementation of the analytical relationships and formulation of the estimators which is not standard in any simulation packages. For further references the interested reader should consult Chapter 11 of (Law 2007).
9.2.4 Control Variates (CV)
The idea is to exploit knowledge of the system by other variables for which the true mean is known and exploit any dependence that it might have with our parameter of interest. Let’s consider a simplified example.
Example 9.5 (Simple Health Clinic) Suppose that we are simulating a heart disease reduction program operating between 10am and Noon. Suppose that 30 patients per day are scheduled at 5 minute intervals. The clinic process is as follows. The patient first visits a clerk to gather their medical information. Then, the patient visits a medical technician where blood pressure and vitals are recorded and it is determined whether or not the patient should visit the nurse. If the patient visits the nurse practitioner, then they receive some medical service and return to a clerk for payment. If the patient does not need to see the nurse practitioner, then the patient goes directly to the clerk for checkout.
Let \(Y_j\) be the utilization of the nurse on the \(j^{th}\) day. We are interested in estimating the utilization of the nurse on any given day.
Let \(X_j\) be the number of patients who consulted with the nurse on the \(j^{th}\) day.
Let \(p\) be the proportion of patients that see the nurse. Because there are 30 patients per day, we have \(E[X_j] = 30p = \mu\), which is a known quantity.
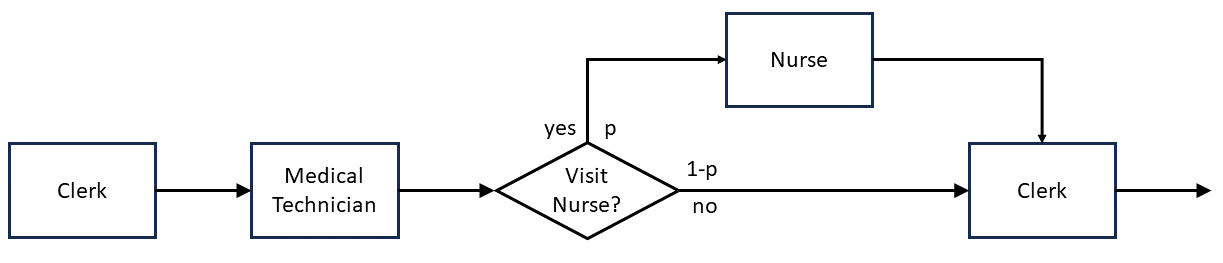
Figure 9.4: Simple Health Clinic
To build up a control variate estimator, define the following random variable, \(Z_j = Y_j + C(X_j - \mu)\), where \(C\) is assumed to be a known constant. Since, our parameter of interest is \(E[Y_j]\) consider \(E[Z_j]\) \[ E[Z_j] = E[Y_j + C(X_j - \mu)] = E[Y_j]+C(E[X_j] -\mu)= E[Y_j] \] Thus, we can estimate \(E[Y_j]\) by observing \(Z_j\), and computing
\[ \bar{Z}= \frac{1}{n}\sum_{i=1}^{n}Z_i \]
The sample average, \(\bar{Z}\), will be an unbiased estimator of \(E[Y_j]\) if \(a\) is a constant known in advance. The random variable \(Z_j\) forms our control variate estimator and the quantity \(X_j\) with known mean \(\mu\) is called the control variate. Intuitively, we can see that \(X_j\) should be related to the utilization of the nurse. For example, if \(X_j\) is high for a particular simulation run, then the nurse should see more patients and thus have a higher utilization. Similarly, if \(X_j\) is low for a particular simulation run, then the nurse should see less patients and thus have a lower utilization. Thus, we can conclude that \(X_j\) is correlated with our quantity of interest \(Y_j\). The linear form \(Z_j = Y_j + C(X_j - \mu)\) adjusts \(Y_j\) up or down based on what is observed for \(X_j\). Why would we want to do this? That is why does using a control variate work?
Consider deriving the variance of our control variate estimator, \(\text{Var}[Z_j]\). This results in:
\[ \text{Var}[Z_j]= \text{Var}[Y_j + C(X_j -\mu)] = \text{Var}[Y_j] + C^2\text{Var}[X_j]+2C\,\text{cov}(Y_j, X_j) \] Rearranging this equation, we have:
\[ \text{Var}[Z_j]= \text{Var}[Y_j] + C(C\text{Var}[X_j]+2\,\text{cov}[Y_j, X_j]) \] Thus, there will be a variance reduction, \(\text{Var}[Z_j] < \text{Var}[Y_j]\), if \(C(C\text{Var}[X_j]+2\,\text{cov}[Y_j, X_j]) < 0\). That is, we will get a variance reduction if this condition is true. There are two cases to consider. If the constant \(C>0\), then the value \(C(C\text{Var}[X_j]+2\,\text{cov}[Y_j, X_j]) < 0\) if
\[C < \frac{-2\text{cov}(Y_j, X_j)}{\text{Var}(X_j)}\]
However, if the constant \(C<0\), then the value \(C(C\text{Var}[X_j]+2\,\text{cov}[Y_j, X_j]) > 0\), if \[C > \frac{-2\text{cov}(Y_j, X_j)}{\text{Var}(X_j)}\] Thus, for a suitably chosen value for \(C\), we can reduce the variance. How do we pick \(C\)? Well, it makes sense to pick the value of \(C\) that minimizes the variance of the estimator, \(\text{Var}[Z_j]\), and thus pick the value of \(C\) that maximizes the variance reduction. To minimize \(\text{Var}[Z_j]\) we can take the derivative with respect to \(C\), and set the derivative equal to 0, and solve for the value of \(C\). \[ \frac{d \, \text{Var}[Z_j]}{d\,C}=2C\,\text{Var}(X_j)+ 2\text{cov}(Y_j, X_j) = 0 \]
\[ C^{*}= \frac{-\text{cov}(Y_j, X_j)}{\text{Var}(X_j)} \]
Substituting \(C^{*}\) into \(\text{Var}[Z_j]\) yields the following:
\[ \text{Var}[Z_j] = \text{Var}[Y_j](1 - \rho^2_{XY}) \] where \(\rho_{XY}\) is the correlation between \(X\) and \(Y\), \(\text{corr}(Y_j, X_j)\). Thus, the variance of our estimator, \(\text{Var}[Z_j]\), depends directly on the correlation between \(Y_j\) and \(X_j\), with more correlation (either positive or negative), the more variance reduction.
Unfortunately \(C^{*}\) is in general unknown and must be estimated from the data. Looking at the form for \(C^{*}\), we need to estimate the numerator,\(\text{cov}(Y_j, X_j)\), and the denominator, \(\text{Var}(X_j)\). Consider estimating \(\text{cov}(Y_j, X_j)\) with the following:
\[ \widehat{cov(Y_j, X_j)}=\frac{\sum_{i=1}^{n}(Y_i - \bar{Y})(X_i - \bar{X})}{n-1} \] And, consider estimating \(\text{Var}(X_j)\) with the following:
\[ \widehat{\text{Var}(X_j)}=\frac{\sum_{i=1}^{n}(X_i - \bar{X})^2}{n-1} \]
Substituting these estimators into the form for \(C^{*}\), this implies an estimator for \(C^{*}\) of:
\[ \hat{C}^{*}= \frac{\sum_{i=1}^{n}(Y_i - \bar{Y})(X_i - \bar{X})}{\sum_{i=1}^{n}(X_i - \bar{X})^2} \]
This formula should remind you of the estimator for the slope of a regression line. From the form for \(Z_j\) it should now be readily apparent that it is essentially assuming a linear relationship and that the optimal value of \(C\) would be the slope of the line (under the assumption that a linear relationship holds). This leads to a more general basis for the form of control variates.
Suppose we want to estimate \(\theta = E[Y]\), and we can also observe some other random variable, \(X\), whose distribution is known, with mean \(\mu = E[X]\). Assume that \(E[Y|X=x] \approx \beta_0 + \beta_1(x-\mu)\). That is, given we observe \(x\), there is an (approximate) linear relationship between \(Y\) and \(X\). This might be justified by thinking of \(g(x) = E[Y|X=x]\) as a function of \(x\) and noting that a linear relationship could at least be possible within a small range of \(\mu\) by expanding \(g(x)\) as a Taylor series about \(\mu\).
\[ g(x) \approx g(\mu) + \frac{d\,g(\mu)}{d\,x}(x- \mu)+\cdots \]
Recall that \(E[Y]= E\bigg[E[Y|X]\bigg] = \beta_0 + \beta_1(X-\mu) = \beta_0 = \theta\). Thus, if we can find an estimator for \(\beta_0\) and the linear relationship is true, then we will have an unbiased estimator for \(\theta\). But, this is exactly the same form of the previously derived control variate estimator. In what follows, we will assume that the linear form, \(E[Y|X=x] = \beta_0 + \beta_1(x-\mu)\) holds.
Assuming that \(E[Y|X=x] = \beta_0 + \beta_1(x-\mu)\) is true, then the control variate estimator for \(\theta = E[Y]\) is \(\hat{\beta_0}\) where:
\[ \hat{\beta_1} = \frac{\sum_{i=1}^{n}(Y_i - \bar{Y})(X_i - \bar{X})}{\sum_{i=1}^{n}(X_i - \bar{X})^2} \]
And,
\[ \hat{\beta_0}= \bar{Y}-\hat{\beta_1}(\bar{X}-\mu) \]
If the linear form for \(E[Y|X=x]\) is true, then it can be shown that \(E[\hat{\beta_0}] = \beta_0\) and \(E[\hat{\beta_1}] = \beta_1\). That is, the control variate estimator \(\hat{\beta_0}\) will be unbiased, and as we have shown, there will be a variance reduction if there is some correlation between the control variate and the quantity of interest. For the technical details of when control variates work and when they do not, please see the following references (Nelson and Pei. 2021) and (Nelson 1990). As noted in those references, if the relationship between \(Y\) and \(X\) is bi-variate normal then the linear form for \(E[Y|X=x]\) is true. In addition, the results can be extended to more than one control variate and if the relationship between the quantity of interest \(Y\) and the controls is multi-variate normal then control variates will again work. Since in many cases the observations of \(Y\) and the controls are averages of within replication data, it is likely that the assumption of normality will be approximately true. In what follows, we indicate some results from (Nelson 1990) and refer the interested reader to that paper for the proofs.
First, if \((Y, X)\) are bivariate normal then it can be shown that:
\[ \text{Var}[\hat{\beta_0}]= (1-\rho^2)\bigg(\frac{n-2}{n-3}\bigg)\frac{\sigma^2_{Y}}{n} \]
From this, we can see that \(\text{Var}[\hat{\beta_0}] \leq \text{Var}[\bar{Y}]\) if and only if \(\rho^2 \geq 1/(n-2)\). Suppose \(n=10\), then \(\rho \geq \sqrt{0.1} = 0.01\). Thus for a small amount of correlation, we can get a variance reduction. These result generalize to more than one control variate. Let \(q\) be the number of control variates. We then formulate the control variate estimator from a linear model of the following form:
\[ Y_i = \beta_0 + \beta_1 (X_1 - \mu_1) + \beta_2 (X_2 - \mu_2) + \cdots + \beta_q (X_q - \mu_q) + \epsilon_i \]
If the \(Y\) and \(X_j\) are multi-variate normally distributed, then
\[ var[\hat{\beta_0}]= (1-R^{2}_{XY})\bigg(\frac{n-2}{n-q-2}\bigg)\frac{\sigma^2_{Y}}{n} \] There will be a variance reduction if \(R^{2}_{XY} \geq \frac{q}{n-2}\), where \(R_{XY}\) is the multiple correlation of \(Y\) on \(X\). The control variate estimator for \(\theta = E[Y]\) will be \(\hat{\beta_0}\), which is the intercept term for the regression. Thus, any standard regression program can be used to compute the estimate. Everything works if the linear relationship holds and the \(Y\) and \(X_j\) are multi-variate normal. If the assumptions do not hold, then the control variate estimator will, in general, be biased. It may have smaller variance, but it may not be unbiased. The recommendation is to use a small number of controls \(1\leq q\leq 10\) and batch the replications if necessary to make the data more normal. If \(n\) is the number of replications and \(n \geq 100\) with \(1\leq q\leq 5\), then batch \(n\) into between \(30 \leq k\leq 60\) batches.
Control variates is a general variance reduction technique. In general within a DEDS situation, there will be many possible controls because any of the input distributions with their known mean values are candidates for controls. With many possible controls, you should think about which input distributions might have more influence over the estimated performance measure as a method for selecting controls. In addition, there is little extra programming that needs to be implemented other than capturing the output of the \(Y\) and the controls \(X\) and their mean values. There is little possibility that control variates will backfire (increase the variance); however, you need to be aware of the previously mentioned possibility of bias. Thus, checking for the normality of the responses and controls is essential. As mentioned, batching the output might be useful. In addition, jackknifing the estimator may help in reducing possible bias. However, these fixes required advanced sophistication from the analyst and will likely need to be implemented.
The KSL has support for using control variates within the context of a DEDS simulation via the ControlVariateDataCollector class. The ControlVariateDataCollector class works in a similar fashion as the ReplicationDataCollector class that was discussed in Section 5.4.1. The following code illustrates its use.
Example 9.6 (Illustrating Control Variates) This example illustrates how to define controls, collect the responses, and compute the control variate estimators using KSL regression constructs.
val model = Model("CV Example")
model.numberOfReplications = 100
val palletWorkCenter = PalletWorkCenter(model)
val cvCollector = ControlVariateDataCollector(model)
cvCollector.addResponse(palletWorkCenter.totalProcessingTime, "TotalTime")
cvCollector.addControlVariate(palletWorkCenter.processingTimeRV, (8.0+ 12.0+ 15.0)/3.0, "PalletTime")
cvCollector.addControlVariate(palletWorkCenter.numPalletsRV, (100.0*0.8), "NumPallets")
model.simulate()
model.print()
println(cvCollector)
val regressionData = cvCollector.collectedData("TotalTime", 20)
println(regressionData)
println()
val regressionResults = cvCollector.regressionResults(regressionData)
println(regressionResults)Notice the use of the method, cvCollector.collectedData("TotalTime", 20). This method prepares the data for a regression analysis. The value 20 tells the method to form 20 batches from the 100 replications into 20 batches of size 5. The following output is the standard half-width report for the 100 replications.
Half-Width Statistical Summary Report - Confidence Level (95.000)%
Name Count Average Half-Width
-------------------------------------------------------------------------
NumBusyWorkers 100 1.9154 0.0133
PalletQ:NumInQ 100 6.9721 0.5609
PalletQ:TimeInQ 100 42.1123 3.3255
Num Pallets at WC 100 8.8875 0.5674
System Time 100 53.7523 3.3254
Total Processing Time 100 497.7907 6.0995
P{total time > 480 minutes} 100 0.7300 0.0885
RandomVariable_4:CVResponse 100 11.6400 0.0299
RandomVariable_6:CVResponse 100 80.8000 0.7316
Num Processed 100 81.8000 0.7316
----------------------------------------------------------------------- As you can see in the following output from the ControlVariateDataCollector class, the data is organized in a manner that permits the application of linear regression.
Control Variate Collector
Responses:
response: TotalTime
Controls:
control: PalletTime mean = 11.666666666666666
control: NumPallets mean = 80.0
Replication Data Collector
Total Processing Time RandomVariable_4:CVResponse RandomVariable_6:CVResponse
0 482.417201 11.991551 75.0
1 461.544205 11.681418 74.0
2 521.417293 11.701470 78.0
3 476.025297 11.699098 80.0
4 534.281150 11.464543 86.0
5 485.735690 11.475689 82.0
6 477.468018 11.645124 80.0
7 482.557886 11.579375 79.0
8 499.628817 11.765892 82.0
9 471.007443 11.603611 78.0
Control Variate Data
TotalTime PalletTime NumPallets
0 482.417201 0.324884 -5.0
1 461.544205 0.014752 -6.0
2 521.417293 0.034803 -2.0
3 476.025297 0.032431 0.0
4 534.281150 -0.202123 6.0
5 485.735690 -0.190977 2.0
6 477.468018 -0.021543 0.0
7 482.557886 -0.087292 -1.0
8 499.628817 0.099225 2.0
9 471.007443 -0.063056 -2.0Thus, you can use your favorite linear regression analysis software to analyze the data and compute the control variate estimate. The KSL has support for performing ordinary least squares regression. In the previously provided code notice that the control variate collector is used to get the regression data via the lines:
val regressionData = cvCollector.collectedData("TotalTime", 20)
println(regressionData)Then, the collector uses the regression data to estimate the regression coefficients.
val regressionResults = cvCollector.regressionResults(regressionData)
println(regressionResults)Below is a snippet of the results of applying the control variate estimator via the estimated regression. The estimate of the intercept term is the control variate estimate.
Regression Results
-------------------------------------------------------------------------------------
Parameter Estimation Results
Predictor parameter parameterSE TValue P-Values LowerLimit UpperLimit
0 Intercept 494.631368 2.792054 177.156788 0.000000 488.740649 500.522088
1 PalletTime 89.977513 44.683070 2.013682 0.060151 -4.295525 184.250550
2 NumPallets 6.943175 1.339181 5.184644 0.000075 4.117751 9.768599
-------------------------------------------------------------------------------------Notice that the estimated response is different than the standard estimate (497.7907) versus (494.631368). In addition,
the half-width of the control variate estimator is smaller. Further analysis should be performed to check the normality assumptions and assess the quality of the estimated value. The KSL RegressionResultsIfc interface has the ability to check the normality of the residuals perform additional regression analysis operations. This analysis is left as an exercise for the reader.
9.2.5 Stratified and Post Stratified Sampling
The idea behind stratified sampling is to take advantage of known properties or characteristics within the underlying population that is being sampled. In stratified sampling, conditional expectation is used to reduce the variance by conditioning on another variable (similar to how control variates use a control variable). In stratified sampling, we sample within the different strata and then form an overall estimate from the estimated value from each strata.
For example, suppose that we were estimating the overall GPA of engineering majors (electrical, mechanical, industrial, computer, chemical, biological, etc.). We know that each major has a different number of students within the college of engineering. If we take a simple random sample from the entire population, we might not observe a particular major just due to the sampling. However, if we knew (or could estimate) the proportion of students within each major, then we could randomly sample from each major (strata) and form a combined GPA estimate from the weighted average of the strata averages. This is the basic idea of stratified sampling. We can control the variability of the estimator by how many students we sample from each major.
Let’s develop some notation to specify these concepts. Recall that \(\theta = E[Y]= E\bigg[E[Y|X]\bigg] = \int E[Y|X=x]d\,F(x)\) where \(F(x)\) is the CDF of some random variable \(X\). Let the range of \(X\) be denoted by \(\Omega\). Divide \(\Omega\) into \(k\) sub-ranges \(L_i\), \(i=1,2,\cdots,k\), such that the \(L_i\) are mutually exclusive and collectively exhaustive. The \(L_i\) are called the strata for \(X\). Using conditional expectation, we have that:
\[ \theta = \sum_{i=1}^kE[Y|x \in L_i]P(X \in L_i) \]
Defining \(p_j = P(X \in L_i)\) and define \(\hat{\theta_j}\) as the estimator of \(E[Y|x \in L_j]\). Then, the stratified estimator is:
\[ \hat{\theta} = \sum_{i=j}^k \widehat{E[Y|x \in L_j]} \, p_j= \sum_{j=1}^k \hat{\theta_j} \, p_j \]
In this situation, \(p_j\) are known constants, computed in advance. This method replaces uncertainty by computing \(p_j\) and estimating \(\hat{\theta_j}\), where \(\hat{\theta_j}\) is the sample average of the observations that fall within strata \(L_j\).
\[ p_j = P(X \in L_i) = \int_{b_{j-1}}^{b_j}f(x)dx \] In stratified sampling, we can pre-determine how many observations to sample within each strata as part of the design of the sampling plan. There is another form of stratified sampling, that classifies each observation after sampling from the overall population as belonging to strata \(L_j\). This approach is called post-stratified sampling.
In post stratified sampling, we observe the IID pairs \((Y_1, X_1), (Y_2, X_2), \cdots ,(Y_n, X_n)\) and form an estimator for \(\theta_j\) by computing the observed sample average for the strata. Let \(Y_{ij}\) be the \(i^{th}\) observation of \(Y\) when \(X \in L_j\), for \(j=1,2,\cdots,k\) and \(i=1,2,\cdots, N_j\), where \(N_j\) is the number of observations of \(Y_i\) in the \(j^{th}\) strata. Note that \(N_j\) is a random variable. The estimator for \(\theta_j\) is:
\[ \hat{\theta_j} = \frac{1}{N_j}\sum_{i=1}^{N} Y_{ij} \]
The post stratified estimator is then
\[\hat{\theta} = \sum_{j=1}^{k}\hat{\theta_j}\,p_j\]
If \(N_j > 0\) for all \(j\), then \(E[\hat{\theta_j}] = \theta_j\) and thus \(E[\hat{\theta}]=\theta\). That is, it will be an unbiased estimator.
There are two main issues when applying stratified sampling: 1) how to form the strata, and 2) how many observations should be sampled in each strata. The formation of the strata is often problem dependent. Then, given the chosen strata a sampling plan (i.e. \(N_j\) for each strata can be analyzed). The key idea for picking the strata is to try to ensure that the means for each strata are different from the overall mean. Let \(\sigma^2_j = var[Y_j |X\in L_j]\) be the within strata variance. One can show that:
\[ \text{Var}(\hat{\theta}) \cong \sum_{j=1}^{k}\frac{p_j \, \sigma^2_j}{n} + \sum_{j=1}^{k}\frac{(1-p_j) \, \sigma^2_j}{n^2} \]
And, that
\[ \text{Var}(\bar{Y}) = \text{Var}(\hat{\theta}) + \sum_{j=1}^{k}\frac{(\theta_j -\theta)^2 \, p_j}{n} \]
Thus, a large spread (difference) for the \(j^{th}\) strata mean from the overall mean \(\theta\) will cause, \(\text{Var}(\bar{Y}) \geq \text{Var}(\hat{\theta})\). You should also pick the number of strata \(k\) to be small such that you can try to guarantee that \(n\,p_j \geq 5\) to ensure that \(N_j > 0\).
In the case of stratified sampling, we can control \(N_j\). That is, \(N_j\) is no longer random and under our control as \(n_j\) for \(j=1,2,\cdots,k\). We pre-plan how much to sample in each \(L_j\) via \(n_j\). One can show that in this case the optimal allocation of \(n\) that minimizes that variance is:
\[ n_j = \frac{n \, p_j \, \sigma_j}{\sum_{i=1}^{k}p_i\,\sigma_i} \] In essence, the minimal variance will occur if \(n_j\) is sampled proportional to \(p_i\,\sigma_i\). For further details of these results, see (Rubinstein and Kroese. 2017) or (Ross 2023). By estimating the within strata variance \(\sigma^2_j = \text{Var}[Y_j |X\in L_j]\) via a pilot run a starting value for \(n_j\) can be obtained. Another (convenient) approach is to allocate the \(n_j\) proportionally as \(n_j = n\,p_j\). As discussed in (Rubinstein and Kroese. 2017), the stratified sampling estimator will be unbiased and should have a variance reduction when compared to the crude Monte Carlo (CMC) estimator.
The stratified sampling method within a Monte Carlo context is relatively straight-forward to implement. The KSL utilities package for random sampling and statistical collection can be used in such an implementation. For the case of a DEDS situation, stratified sampling has less direct appeal. Although the post-stratified sampling method could be automated by capturing the response \(Y_j\) and generated \(X\) from the simulation (within replication data), it is not straight-forward to connect the generated \(X\) values with the responses. Thus, the KSL does not provide constructs to specifically implement this variance reduction technique.
9.2.6 Conditional Expectation (CE)
For completeness, this section discusses another less general form of variance reduction technique: conditional expectation. As we will see, this technique is very problem dependent. Thus, this section presents the concepts within the context of a particular example. For more of the theory behind this technique, we refer the interested reader to (Rubinstein and Kroese. 2017) or (Ross 2023). Like stratified sampling and control variates this method work on using \(E[Y|X]\). Recall \(\theta = E[Y]= E\bigg[E[Y|X]\bigg]\). It can be shown, see (Ross 2023), that \(\text{Var}[E[Y|X]] \leq \text{Var}[\bar{Y}]\). Thus, if we know the function \(E[Y|X=x]\) and have a sample \(X_1, X_2,\cdots, X_n\), then we can use:
\[ \hat{\theta} = \frac{1}{n}\sum_{i=1}^{n}E[Y|X_i] \] This technique relies on being able to derive the function \(E[Y|X=x]\) from the problem situation, which can be very problem dependent. We will demonstrate this via an example involving a stochastic activity network.
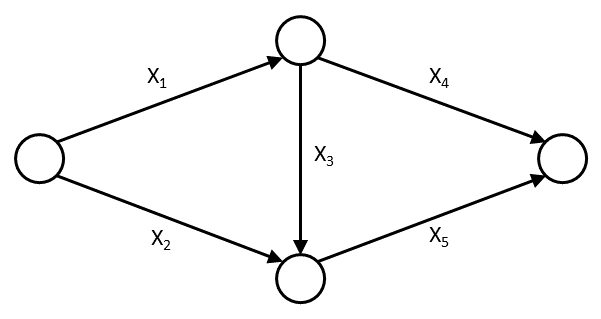
Figure 9.5: Example Stochastic Activity Network
Let \(X_i\) be the time required to complete arc \(i\). Assume that the \(X_i\) are independent. A path through an activity network is a sequence of arcs going from a source node to a sink node. For the example network, we have three paths.
- Path 1: \(Y_1 = X_1 + X_4\)
- Path 2: \(Y_2 = X_1 + X_3 + X_5\)
- Path 3: \(Y_3 = X_2 + X_5\)
Activity networks are often simulated in order to observe the longest path,e.g. \(Y = max(Y_1, Y_2, Y_3)\) and estimate quantities such as \(E[Y]\) and \(P(Y \leq t)\). A crude Monte Carlo algorithm for estimating \(E[Y]\) and \(P(Y \leq t)\) is as follows.
- Let \(P_j\) be the arcs on path \(j\); choose t; let \(c=0\); \(sum = 0\)
for \(n=1\) to \(k\);
- generate \(X_i \sim F_i(x)\), \(i=1,2,3,4,5\)
- compute \(Y_j = \sum_{i\in P_j}X_i\), for \(j=1,2,3\)
- let \(Y = max(Y_1, Y_2, Y_3)\)
- if (\(Y \leq t\)) then \(c=c+1\); \(sum = sum + Y\)
end for;
- \(\widehat{P(Y \leq t)} = c/k\)
- \(\bar{Y} = sum/k\)
In what follows, we will develop functional form for \(E[Y|X=x]\) so that the conditional expectation variance reduction technique can be applied. We begin by developing the distribution for \(P(Y \leq t)\). The distribution of \(Y\) the maximum path length is defined as:
\[ P(Y \leq t) = P(max(Y_1, Y_2, Y_3)\leq t)=P(Y_1 \leq t, Y_2 \leq t, Y_3 \leq t) \]
Thus, the \(Y_i\) are not independent random variable because they share arcs. This dependence can be exploited for the application of CE. Another way to write \(P(Y \leq t)\) can be useful. Define an indicator function \(g(X_1, X_2, X_3, X_4, X_5)\) as follows:
\[ g(X_1, X_2, X_3, X_4, X_5)=\begin{cases} 1 & \text{if } \, Y \leq t\\ 0 & \text{if } \, Y > t\\ \end{cases} \] Now, define \(f_i(x_i)\) as the distribution function the length, \(X_i\), of each arc \(i\). Then, the indicator function \(g(\cdot)\) can be used to define \(P(Y \leq t)\) as follows:
\[ P(Y \leq t) = \int_0^{\infty}\int_0^{\infty}\int_0^{\infty}\int_0^{\infty}\int_0^{\infty}g(X_1, \cdots, X_5)\,f_1(x_1)f_2(x_2)\cdots f_5(x_5)\,dx_1\cdots dx_5 \] Thus, \(P(Y \leq t) = E[g(X_1, \cdots, X_5)]\). This form \(P(Y \leq t) = E[g(X_1, \cdots, X_5)]\) allows us to more easily see the conditional expectation possibilities.
Consider \(E[g(X_1, \cdots, X_5)|X_1=x_1, X_5=x_5]\), which is the conditional expectation of \(g(\cdot)\) given arcs one and five. Notice from Figure 9.5 that \(X_1\) and \(X_5\) occur in each of the three paths. That is, arcs one and five are common on the three paths.
Note that by conditional expectation, we can write \(P(Y \leq t) = E_{X_1,X_5}\bigg[E[g(X_1, \cdots, X_5)|X_1, X_5]\bigg]\) and that \(E[g(X_1, \cdots, X_5)|X_1=x_1, X_5=x_5]\) can be written as:
\[ \begin{aligned} E[g(X_1, \cdots, X_5)|X_1=x_1, X_5=x_5] &= P(Y \leq t|X_1=x_1, X_5=x_5)\\ &= P(Y_1 \leq t, Y_2 \leq t, Y_3 \leq t|X_1=x_1, X_5=x_5)\\ &= P(X_1 + X_4 \leq t, X_1+X_3+X_5 \leq t, X_2+X_5 \leq t|X_1=x_1, X_5=x_5)\\ &= P( X_4 \leq t-x_1, X_3 \leq t-x_1-x_5, X_2\leq t-x_5)\\ &= P( X_4 \leq t-x_1)P(X_3 \leq t-x_1-x_5)P( X_2\leq t-x_5)\\ &= F_4(t-x_1)F_3(t-x_1-x_5)F_2( t-x_5)\\ \end{aligned} \] Notice that \(E[g(X_1, \cdots, X_5)|X_1=x_1, X_5=x_5]\) is simply a function of \(x_1\) and \(x_5\). Thus after observing \(x_1\) and \(x_5\), we can average over this expression and compute \(P(Y \leq t)\). A simple algorithm for this can be written as.
- \(sum = 0\)
for \(n=1\) to \(k\);
- generate \(X_1\) and \(X_5\)
- sum = sum + \(F_4(t-x_1)F_3(t-x_1-x_5)F_2( t-x_5)\)
end for;
- \(\widehat{P(Y \leq t)} = sum/k\)
The conditional expectation estimator (if found) will guarantee a variance reduction. The amount of variance reduction is problem dependent.
Since this technique is problem dependent, the KSL does not provide general support for applying CE; however, as noted in the simple algorithms that were presented, the KSL support for generating random variates and collecting statistics would be essential in such an implementation. The difficulty of applying CE to static Monte Carlo situations is based on the problem situation but relatively straight-forward if the conditional expectation function can be derived; however, CE has received limited application in the more general DEDS situation.
9.2.7 Importance Sampling (IS)
The final variance reduction technique to be discussed is general in nature; however, although it has many applications its application is significant within a specific static Monte Carlo situation, specifically the estimation of the area of a function.
\[ \theta = \int\limits_{a}^{b} g(x) \mathrm{d}x \] Recall that the crude or simple Monte Carlo evaluation of an integral utilizes the uniform distribution:
\[ f_{X}(x) = \begin{cases} \frac{1}{b-a} & a \leq x \leq b\\ 0 & \text{otherwise} \end{cases} \]
Therefore,
\[ E_{X}\lbrack g(x) \rbrack = \int\limits_{a}^{b} g(x)f_{X}(x)\mathrm{d}x = \int\limits_{a}^{b} g(x)\frac{1}{b-a}\mathrm{d}x \] Defining \(Y = \left(b-a\right)g(X)\) and substituting, yields, \[ \begin{aligned} E\lbrack Y \rbrack & = E\lbrack \left(b-a\right)g(X) \rbrack = \left(b-a\right)E\lbrack g(X) \rbrack\\ & = \left(b-a\right)\int\limits_{a}^{b} g(x)\frac{1}{b-a}\mathrm{d}x = \int\limits_{a}^{b} g(x)\mathrm{d}x = \theta\end{aligned} \] Therefore, by estimating the expected value of \(Y\) with the sample average of the \(Y_i\) values, we can estimate the desired integral. Importance sampling does this same thing but does not necessarily use the \(U(a,b)\) distribution. Importance sampling rewrites the integration as follows:
\[ \theta = \int\limits_{a}^{b} g(x) \mathrm{d}x = \int\limits_{a}^{b}\frac{g(x)}{w(x)}w(x)\mathrm{d}x \] The function \(w(x)\) is a probability density function defined over \([a, b]\), where \(X\sim w(x)\). Instead of defining \(Y = \left(b-a\right)g(X)\), we define \(Y\) as:
\[ Y = \frac{g(X)}{w(X)} \]
Therefore:
\[ E[Y] = E_X\bigg[\frac{g(X)}{w(X)}\bigg]= \int\limits_{a}^{b}\frac{g(x)}{w(x)}w(x)\mathrm{d}x=\int\limits_{a}^{b} g(x) \mathrm{d}x =\theta \]
To estimate \(\theta\), we use \(\bar{Y}\), where \(X_i\sim w(x)\) and:
\[ \hat{\theta} = \bar{Y}(n) = \frac{1}{n}\sum_{i=1}^{n}Y_i=\frac{1}{n}\sum_{i=1}^{n}\frac{g(X_i)}{w(X_i)} \] A judicious choice of \(w(x)\) can reduce the variance of the estimator \(\hat{\theta}\) allowing us to get more precision in the same amount of samples. While illustrated for 1-D integration, this same theory applies to higher dimensional integrals. However, higher dimensional integrals requires that \(\vec{X} \sim w(\vec{X})\) be a multi-variate distribution.
In general, any function \(g(x)\) can be factored into two functions such that \(g(x) = h(x)f(x)\) where \(f(x)\) is a probability density function. The optimal choice for \(w(x)\) is the function \(f(x)\). However, to find this function, we would in general need to know \(\theta\), which is the thing we are trying to estimate.
A good choice for \(w(x)\) is one that will cause more samples when \(g(x)\) is large and sample infrequently when \(g(x)\) is small. That is, sample more in the more important areas. This is the genesis for the name importance sampling. Let’s take a look at an example to illustrate these insights.
Suppose we want to integrate the function \(g(x) = x^2\) over the range \(0\leq x \leq 1\). This is easy because we can compute the answer:
\[ \theta = \int\limits_{0}^{1} g(x) \mathrm{d}x = \int\limits_{0}^{1}x^2\mathrm{d}x=\frac{x^3}{3}\bigg|_0^1 = \frac{1}{3} \]
The crude MC estimator has the following factorization, \(g(x) = h(x)\, f(x)\), where \(h(x) = x^2\) and:
\[ f_{X}(x) = \begin{cases} \frac{1}{1-0} & 0 \leq x \leq 1\\ 0 & \text{otherwise} \end{cases} \]
Thus, the crude MC estimator for \(\theta = E_f[h(X)]\) is:
\[ \bar{Y}(n) = \frac{1}{n}\sum_{i=1}^{n}h(X_i)=\frac{1}{n}\sum_{i=1}^{n}g(X_i) \] Let’s derive the variance of the crude MC estimator.
\[ \text{Var}(\bar{Y}(n)) =\frac{1}{n}\text{Var}(g(X_i))=\frac{1}{n}\bigg(E[g^2(X)]-\theta^2\bigg) \]
\[ E[g^2(X)] = \int_0^{1}g^2(x)dx=\int_0^{1}x^4dx=\frac{x^5}{5}\bigg|_0^1 = \frac{1}{5} \]
\[ \text{Var}(\bar{Y}(n)) =\frac{1}{n}\bigg(\frac{1}{5}-\theta^2\bigg) =\frac{1}{n}\bigg(\frac{1}{5}-\frac{1}{9}\bigg)=\frac{1}{n}\bigg(\frac{4}{45}\bigg) \]
We must try to do better than this value using importance sampling. Also, note that in general, we would not know \(\theta\) to do this calculation.
The effectiveness of importance sampling hinges on picking the proposal distribution \(w(x)\). The goal is to pick a proposal density \(w(x)\) that improves on \(\text{Var}(\bar{Y}(n))\) of the crude MC estimator. Consider the following possibility:
\[ w(x) = \begin{cases} 2x & 0 \leq x \leq 1\\ 0 & \text{otherwise} \end{cases} \] Clearly, this \(w(x)\) is a probability density function since \(\int_0^{1}w(x)dx=\int_0^{1}2x\,dx=\frac{2x^2}{2}\bigg|_0^1 = 1\). The importance sampling estimator is based on the following:
\[ \hat{\theta} = \bar{Y}(n) = \frac{1}{n}\sum_{i=1}^{n}Y_i=\frac{1}{n}\sum_{i=1}^{n}\frac{g(X_i)}{w(X_i)} \] Let’s derive the variance of this estimator based on the given function \(w(x)\). Using the definition of variance, we have:
\[ \begin{aligned} \text{Var}(\hat{\theta}) &=\frac{1}{n}\text{Var}\bigg( \frac{g(X_i)}{w(X_i)}\bigg)=\frac{1}{n}\bigg(E_w\Bigg[\Bigg(\frac{g(X_i)}{w(X_i)}\Bigg)^2\Bigg]-\theta^2\bigg)\\ &=\frac{1}{n}\bigg( \int_0^{1}\frac{g^2(x)}{w^2(x)}\,w(x) \,dx -\theta^2\bigg) \end{aligned} \]
Now, we need to complete this derivation by deriving the second moment for the example problem.
\[ \int_0^{1}\frac{g^2(x)}{w(x)} \,dx=\int_0^{1}\frac{x^4}{2x}\,dx = \int_0^{1}\frac{x^3}{2}\,dx =\frac{x^4}{8}\bigg|_0^1 = \frac{1}{8} \] Therefore:
\[ \text{Var}(\hat{\theta}) =\frac{1}{n}\bigg(\frac{1}{8}-\theta^2\bigg) =\frac{1}{n}\bigg(\frac{1}{8}-\frac{1}{9}\bigg)=\frac{1}{n}\bigg(\frac{1}{72}\bigg) \] Let’s look at the ratio of the variances of the two competing estimators:
\[ VR = \frac{\text{Var}(\hat{\theta})}{\text{Var}(\bar{Y}(n))}=\frac{\frac{1}{n}\bigg(\frac{1}{72}\bigg)}{\frac{1}{n}\bigg(\frac{4}{45}\bigg)}=\frac{4}{3240}< 1 \]
There will be a significant variance reduction with this choice of \(w(x)\) over using the standard uniform distribution.
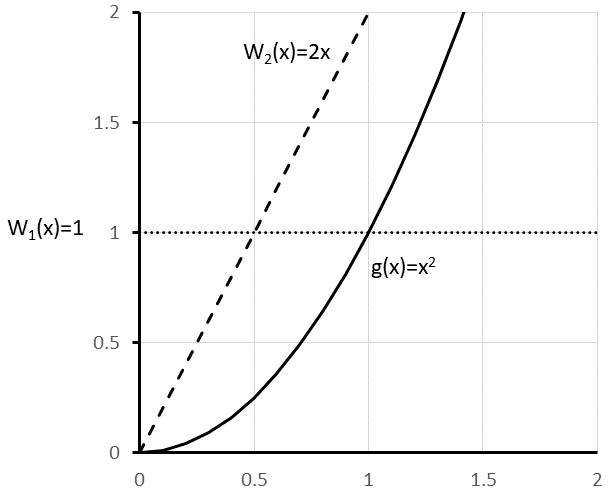
Figure 9.6: Importance Sampling Based on w(x)
Figure 9.6 shows the two proposal functions \(w_1(x)\) (\(U(0,1)\)) and \(w_2(x) = 2x\) relative to \(g(x)\). We can see that the closer the proposal distribution is to \(g(x)\) as the intuition behind why there is such a dramatic variance reduction.
(Rubinstein and Kroese. 2017) devotes considerable time to the topic of importance sampling. The most interesting aspect of their treatment is the discussion on sequential importance sampling, which dynamically updates the proposal distribution as the sampling procedure proceeds in a manner that tries to converge towards the optimal proposal distribution. We encourage the interested reader to explore the reference for further details.
The KSL supports the application of importance sampling via the MC1DIntegration and MCMultiVariateIntegration classes. Section 3.8 described the use of the MC1DIntegration, which permits the application of importance sampling by allowing the user to provide \(h(x)\), where
- \(w(x)\) is the probability distribution for the random variable supplied by the sampler,
- \(g(x)\) is the function that needs to be integrated, and
- \(h(x)\) is a factorization of \(g(x)\) such that \(g(x) = h(x)*w(x)\), that is \(h(x) = g(x)/w(x)\)
The exercises will ask the reader to apply importance sampling to some of the problems already faced in Chaper 3. The KSL also supports the application of importance sampling to multi-dimensional integrals; however, since that topic requires the concepts of how to generate from multi-variate distributions, we will defer that discussion until after the next section.