D.4 CSV, Excel, and Tabular Data Files
The KSL also has simple utilities to work with comma separated value (CSV) files and Excel files. The underlying CSV file processing library used by the KSL is Commons CSV. The KSL provision of working with CSV files is not meant to replace the functionality of those libraries. Instead, the purpose is to provide a simple facade so that users can do some simple processing without worrying about the complexities of a full featured CSV library. Figure D.3 illustrates the functions and properties of the CSVUtil object
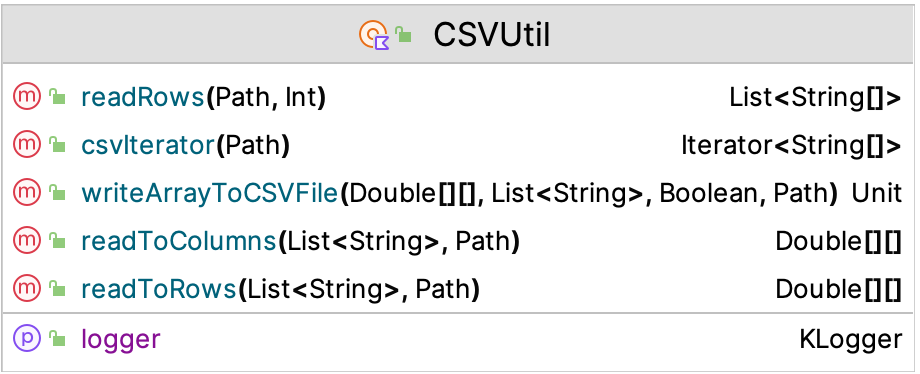
Figure D.3: CSVUtil Class
Assuming that the CSV data is organized with first row as a header and each subsequent row as the data for each column as follows:
"x", "y"
1.1, 2.0
4.3, 6.4The KSL class CSVUtil has the following functions:
readRows() : List<Array<String>>Reads all rows into list holding the rows within an array of stringsreadRows() : Array<DoubleArray>Reads all rows into array holding the rows within an array of doublesreadToColumns() : Array<DoubleArray>reads all of the rows and transposes them into the columnswriteArrayToCSVFile(array: Array<DoubleArray>)will write a 2-D array to a file with the CSV format, allowing an optional header and whether quotes are added to strings.csvIterator(): Iterator<Array<String>>will iterate through a CSV file.
The following code illustrates the use of the CSVUtil class. An instance of a NormalRV random variable is used to make a 5 row, 4 column matrix of normal \(\mu = 0\) and \(\sigma = 1\) random variates.
val n = NormalRV()
val matrix = n.sampleAsColumns(sampleSize = 5, nCols = 4)
for(i in matrix.indices){
println(matrix[i].contentToString())
}
val h = listOf("col1", "col2", "col3", "col4")
val p = KSL.csvDir.resolve("data.csv")
CSVUtil.writeArrayToCSVFile(matrix, header = h.toMutableList(), pathToFile = p)
println()
val dataAsList: List<Array<String>> = CSVUtil.readRowsToListOfStringArrays(p, skipLines = 1)
val m = KSLArrays.parseTo2DArray(dataAsList)
for(i in matrix.indices){
println(m[i].joinToString(prefix = "[", postfix = "]"))
}The contents of the matrix are printed to console. The header is made for the CSV file and then the matrix is written to the file using the CSVUtil function to write an array to a CSV file. Then, the CSVUtil object is used to read the data into list of strings, which are parsed to double values. You can use the Commons CSV functionality to read and write values via its API. The approach illustrated here is only meant for simple file processing.
Excel file operations are available within the KSL through the Apache POI library. The KSL provision of working with Excel files is not meant to replace the functionality of the POI library. Instead, the purpose is to provide a simple facade so that users can do some simple processing without worrying about the complexities of a full featured POI library. Figure D.4 illustrates the functions and properties of the ExcelUtil object.
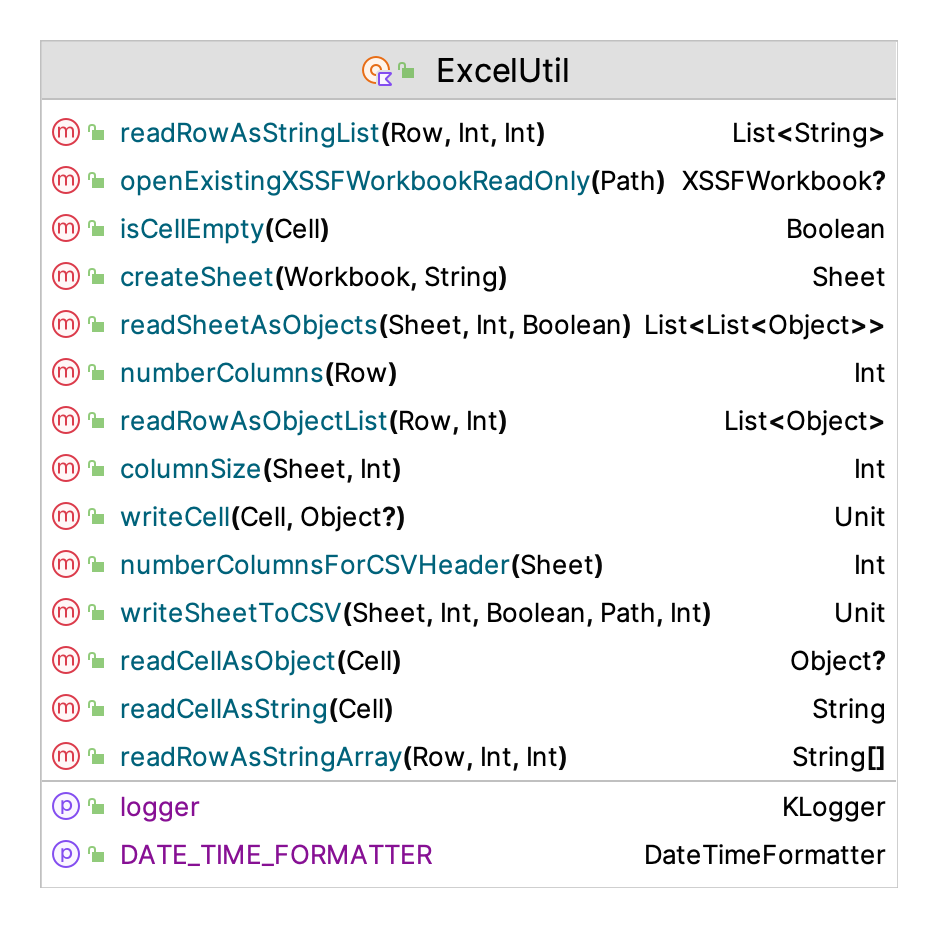
Figure D.4: ExcelUtil Class
The KSL class ExcelUtil provides the basic functions primarily concerned with reading and writing tabular data:
createSheet(workbook: Workbook, sheetName:String)Creates a sheet within the workbook with the name.writeSheetToCSV()Treats the columns as fields in a csv file, writes each row as a separate csv row in the resulting csv filewriteCell()Writes the object to the Excel cellreadCellAsObject() : Any?the data in the form of an objectreadCellAsString() : Stringthe data in the form of a StringreadRowAsObjectList() : List<Any?>an list of strings representing the contents of the cellsreadRowAsStringArray() : Array<String?>an array of strings representing the contents of the cellsreadRowAsStringList() : List<String?>a list of strings representing the contents of the cellsreadSheetAsObjects() : List<List<Any?>>a list of lists of the objects representing each cell of each row of the sheetcolumnSize()number of rows that have data in a particular column as defined by not having a null cell.
To use the ExcelUtil object, it is useful to know how the Apache POI library works because you need to know how to create workbooks. The functionality of the POI library is also exposed as part of the KSL API. The main use of the object ExcelUtil within the KSL is for importing and exporting database tables and record sets to Excel.
Comma separated value (CSV) files and Excel files are commonly used to store data in a tabular (row/column) format. The KSL also provides some basic functionality for reading and writing tabular files.
A common programming necessity is to write or read data that is organized in rows and columns. While libraries that support CSV file processing are readily available, it is sometimes useful to have a quick and easy way to write (or read) tabular data that is not as sophisticated as a database. While Excel files also provide this ability, using the Apache POI may be more than is required. To make this type of file processing easier, the KSL provides a general interface for representing tabular data as a data class via the TabularData class. In addition, the TabularFile, TabularOutputFile, and TabularInputFile classes permit simple row oriented reading and writing of tabular data.
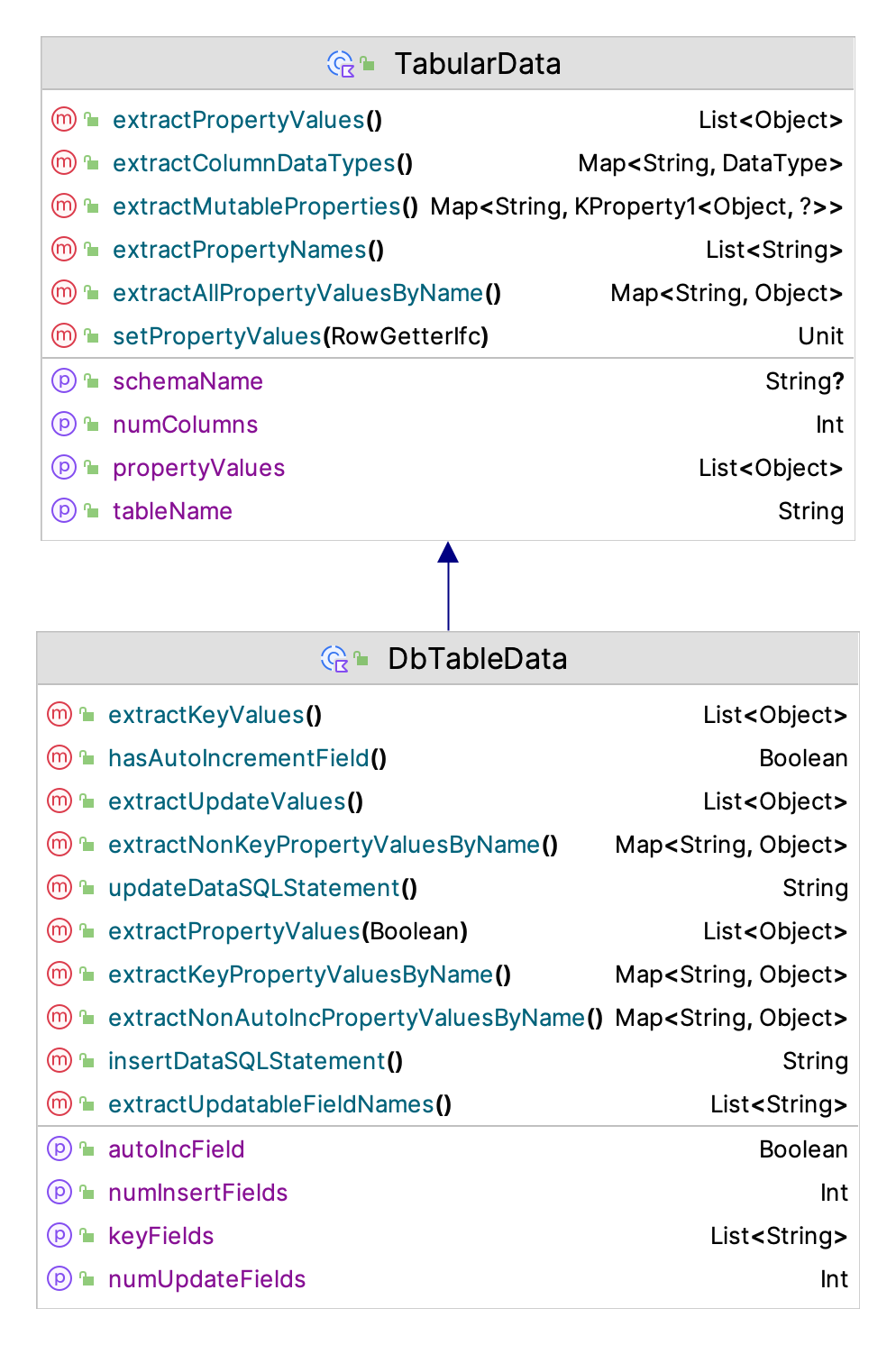
Figure D.5: TabularData Class
Figure D.5 illustrates the functions and properties of the TabularData class. The basic usage of this class is to subclass a data class from it to define the contents of a row of data. This can be used for database processing as well as for working with the tabular file classes.

Figure D.6: Tabular File Classes
Figure D.6 illustrates the functions and properties of the classes for working with tabular data stored in files.
The following code illustrates how to make a tabular file with 5 columns. The first three columns hold numeric data. The fourth column holds text, and the fifth column holds numeric data. The enum DataType defines two types of data to be held in columns: numeric or text. This covers a vast majority of simple computing needs.
val path: Path = KSL.outDir.resolve("demoFile")
// configure the columns
val columns: MutableMap<String, DataType> = TabularFile.columns(3, DataType.NUMERIC).toMutableMap()
columns["c4"] = DataType.TEXT
columns["c5"] = DataType.NUMERIC
// make the file
val tif = TabularOutputFile(columns, path)
println(tif)The columns() function is used to define the columns as a map of column names and the data types. This describes a type of column within the tabular file.
The numeric type should be used for numeric data (float, double, long, int, etc.). In addition, use the numeric type for boolean values, which are stored 1.0 = true, 0.0 = false). The text type should be used for strings and date/time data. Date and time data is saved as ISO8601 strings (“YYYY-MM-DD HH:MM:SS.SSS”). If you need more type complexity, you should use a database or some other more advanced serialization method such as JSON, Parquet, or Arrow.
The following code creates some random data and writes rows of data to the file. The RowSetterIfc interface is use in that it allows for the writing of any numeric columns and any text columns as separate row operations.
// needed for some random data
val n = NormalRV(10.0, 1.0)
val k = 15
// get a row
val row: RowSetterIfc = tif.row()
// write some data to each row
println("Writing rows...")
for (i in 1..k) {
// reuse the same row, many times
// can fill all numeric columns
row.setNumeric(n.sample(5))
// can set specific columns
row.setText(3, "text data $i")
// need to write the row to the buffer
tif.writeRow(row)
}
// don't forget to flush the buffer
tif.flushRows()
println("Done writing rows!")The tabular file package also allows for the defintion of the data schema via data class. The type of the properties of the data class are translated to either text or numeric columns. The following code illustrates this functionality. Here a data class is used to define a text field and a numeric field, which are then written to the file.
val path: Path = KSL.outDir.resolve("TabularDataFile")
data class SomeData(var someText: String = "", var someData: Double = 0.0): TabularData("SomeData")
val rowData = SomeData()
// use the data class instance to define the columns and their types
val tof = TabularOutputFile(rowData, path)
println(tof)
// needed for some random data
val n = NormalRV(10.0, 1.0)
val k = 15
// write some data to each row
println("Writing rows...")
for (i in 1..k) {
// reuse the same row, many times
// can fill all numeric columns
rowData.someData = n.value
rowData.someText = "text data $i"
// need to write the row to the buffer
tof.writeRow(rowData)
}
// don't forget to flush the buffer
tof.flushRows()
println("Done writing rows!")As long as the data class is compatible with the rows of the file, then the same approach can be used to read in the data as illustrated in the next code snippet.
val tif = TabularInputFile(path)
println(tif)
// TabularInputFile is Iterable and foreach construct works across rows
println("Printing all rows from an iterator using data class")
for (row in tif.iterator()) {
rowData.setPropertyValues(row)
println(rowData)
}
println()Reading data from the file has a bit more functionality through some useful iterators. The following code opens a tabular file and iterates the rows.
val path: Path = KSL.outDir.resolve("demoFile")
val tif = TabularInputFile(path)
println(tif)
// TabularInputFile is Iterable and foreach construct works across rows
println("Printing all rows from an iterator")
for (row in tif.iterator()) {
println(row)
}
println()You can fetch specific rows or a subset of rows. Multiple iterators can be active at the same time.
// You can fetch rows as a list
println("Printing a subset of rows")
val rows: List<RowGetterIfc> = tif.fetchRows(1, 5)
for (row in rows) {
println(row)
}
println()You can start the iterator at a particular row.
println("Print starting at row 9")
val iterator: TabularInputFile.RowIterator = tif.iterator(9)
while (iterator.hasNext()) {
println(iterator.next())
}
println()You can grab various columns as arrays.
println("Printing column 0")
val numericColumn: DoubleArray = tif.fetchNumericColumn(0, 10, true)
for (v in numericColumn) {
println(v)
}You can write the data to an Excel workbook.
try {
tif.exportToExcelWorkbook("demoData.xlsx", KSL.excelDir)
} catch (e: IOException) {
e.printStackTrace()
}You can pretty print rows of the data and export the data to a CSV file.
tif.printAsText(1, 5)
val printWriter: PrintWriter = KSL.createPrintWriter("data.csv")
tif.exportToCSV(printWriter, true)
printWriter.close()You can even convert the tabular data to an SQLLite database or turn the data into a data frame.
try {
val database: DatabaseIfc = tif.asDatabase()
} catch (e: IOException) {
e.printStackTrace()
}
println()
println("Printing a data frame version")
val df = tif.asDataFrame()
println(df)Much of this functionality is used within the implementation of the KSL database implementation, which will be discussed in a subsequent section. Since we just mentioned data frames, we discuss that functionality in the next section.